- a (alpha)
How low the p value must be before the sample result is considered unlikely in null hypothesis testing.
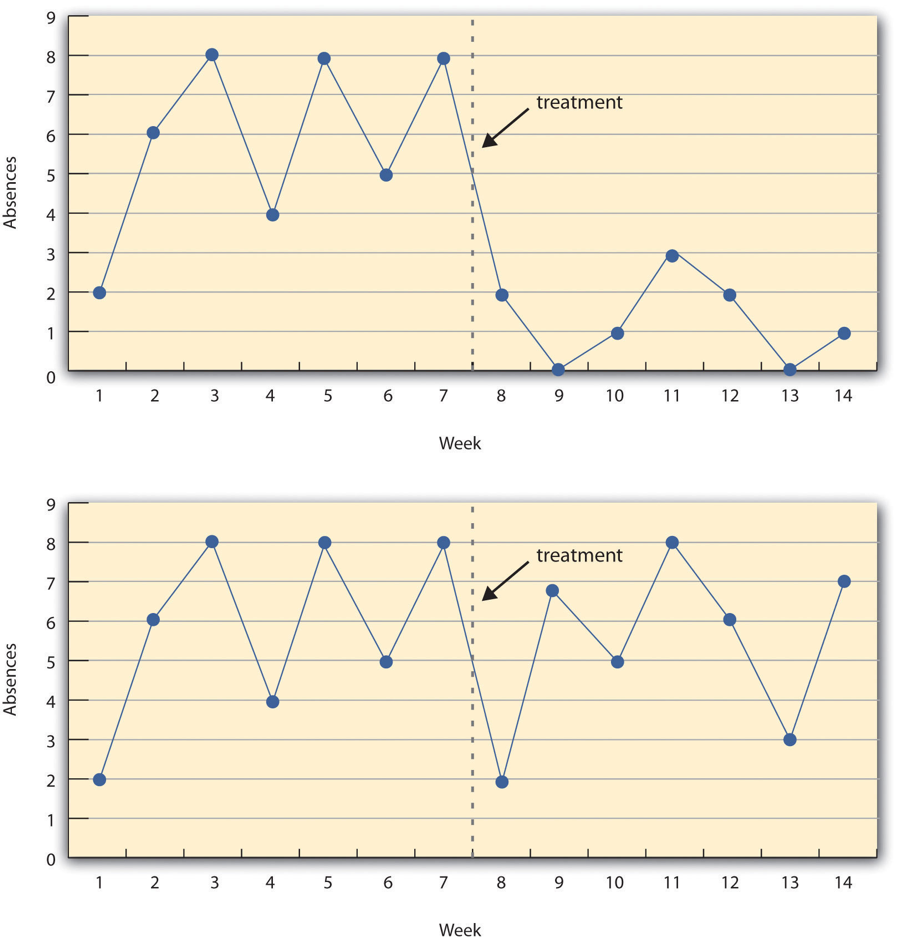
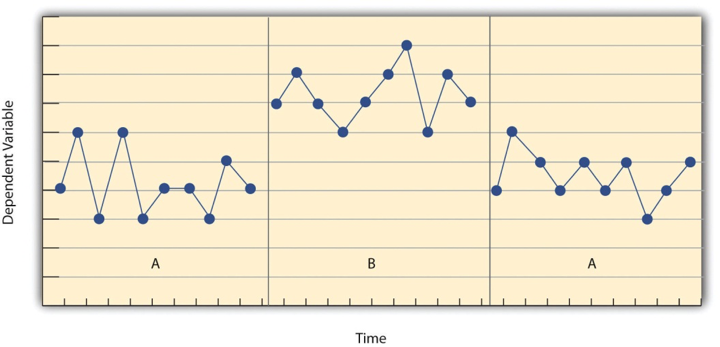
- ABA design (reversal design)
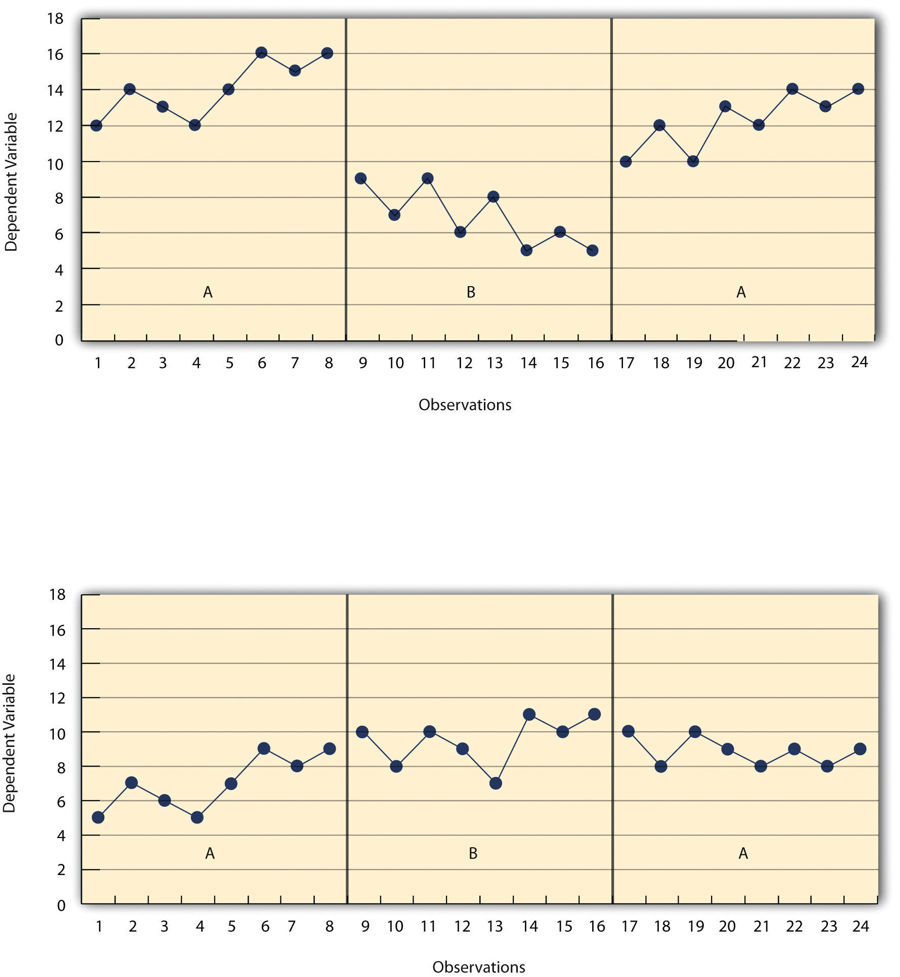
A study method in which the researcher gathers data on a baseline state, introduces the treatment and continues observation until a steady state is reached, and finally removes the treatment and observes the participant until they return to a steady state.
- Abstract
A summary of a research study.
- ACT-R
A comprehensive theory of human cognition that is akin to a programming language, within which more specific models can be created.
- Alternating Treatments Design
Two or more treatments are alternated relatively quickly on a regular schedule.
- Alternative Hypothesis
The idea that there is a relationship in the population and that the relationship in the sample reflects this relationship in the population.
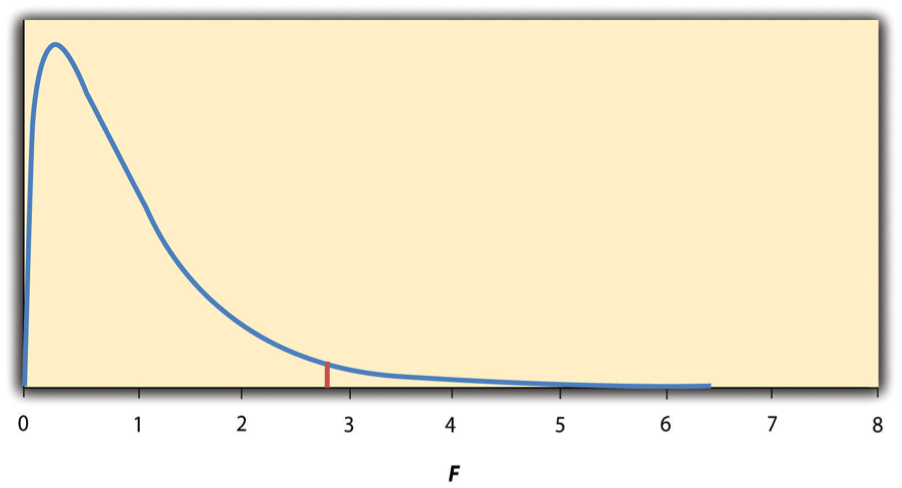
- Analysis of Variance (ANOVA)
Most common null hypothesis test when there are more than two groups or condition means to be compared.
- APA Ethics Code
A code first published in 1953 which includes approximately 150 specific ethical standards that psychologists and their students are expected to follow.
- APA Style
A set of guidelines for writing in psychology and related fields.
- Appendix
Part of a research report which contains supplemental material.
- Applied Behaviour Analysis
Starting in the 1960s, researchers began using single-subject techniques to conduct applied research with human subjects.
- Applied Research
Research conducted primarily to address some practical problem.
- Archival Data
Data that have already been collected for some other purpose.
- Autonomy
A person’s right to make their own choices and take their own actions free from coercion.
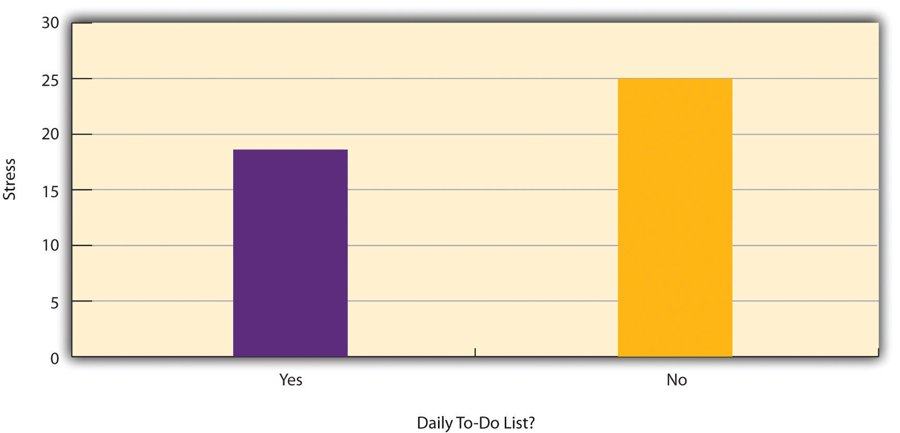
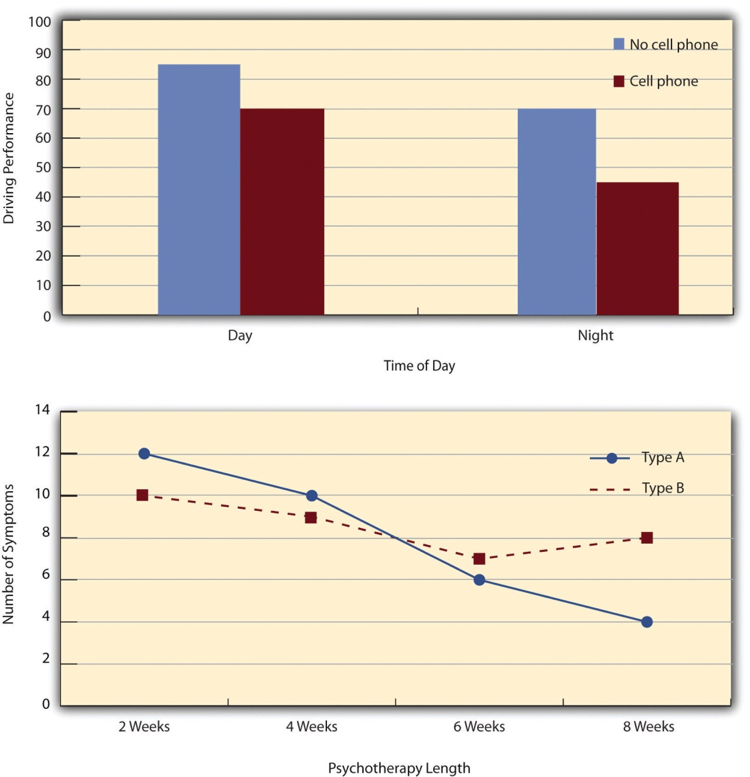
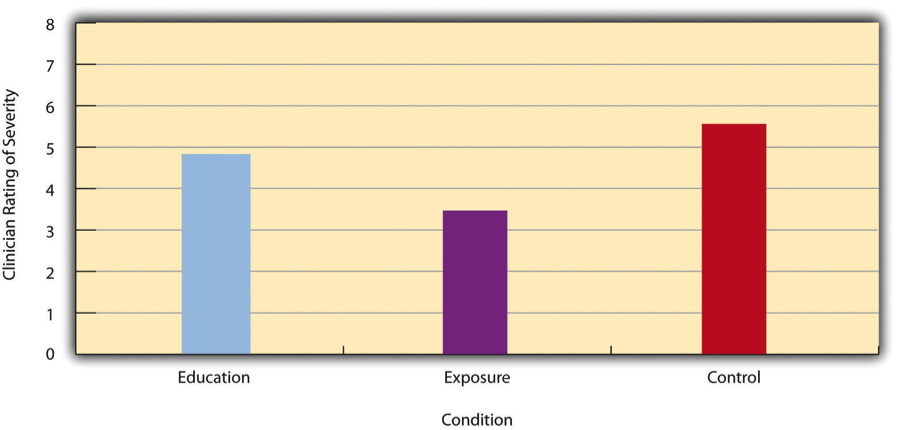
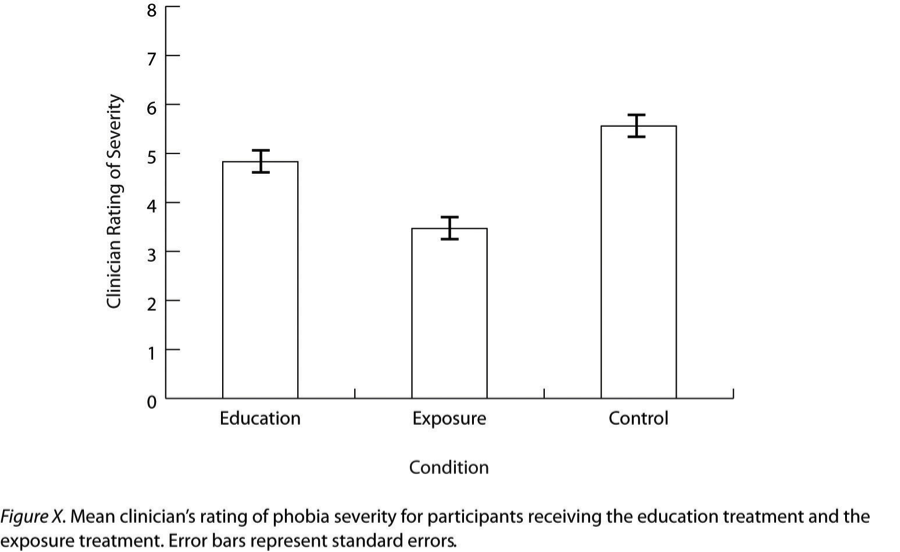
- Bar Graph
A figure in which the heights of the bars represent the group means.
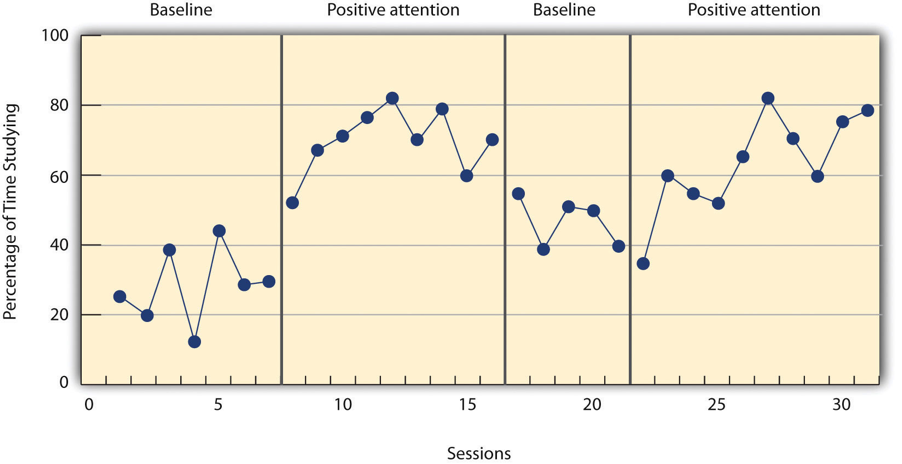
- Baseline
The level of responding before any treatment is introduced and therefore acts as a kind of control condition.
- Basic Research
In psychology, research conducted for the sake of achieving a more detailed and accurate understanding of human behaviour, without necessarily trying to address any particular problem.
- Bayesian Statistics
An approach in which the researcher specifies the probability that the null hypothesis, and any important alternative hypotheses, are true before conducting the study and then updates the probabilities based on the data from the study.
- Behavioural Measures
Measures in which some aspect of participants’ behaviour is observed and recorded.
- Belmont Report
Published in 1978 in the United states, this explicitly recognized the principle of seeking justice including the importance of conducting research in a way that distributes risks and benefits fairly across different groups at the societal level.
- Between-subjects Experiment
An experiment in which each participant is only tested in one condition.
- Between-subjects Factorial Design
All of the independent variables are manipulated between subjects.
- Blindsight
People with damage to their visual cortex are often able to respond to visual stimuli that they do not consciously see.
- Block Randomization
All the conditions of an experiment occur once in the sequence before any of them is repeated.
- BRUSO
A guideline for questionnaire items that suggests they should be brief, relevant, specific, and objective.
- Bystander effect
The more people who are present at an emergency situation, the less likely it is that any one of them will help.
- Carryover Effect
An effect of being tested in one condition on participants’ behaviour in later conditions.
- Case Study
A detailed description of an individual, which can include both qualitative and quantitative analyses.
- Categorical Variable
A quality that is typically measured by assigning a category label to each individual.
- Central Tendency
The point around which the scores in the distribution tend to cluster, also called the average.
- Clinical Practice of Psychology
The diagnosis and treatment of psychological disorders and related problems.
- Closed-ended Items
A questionnaire item that asks a question and provides a set of response options for participants to choose from.
- closing
The end of the introduction, where the research question is reiterated and the method is commented upon.
- Cluster Sampling
A method of probability sampling in which larger clusters of individuals are randomly sampled and then individuals within each cluster are randomly sampled.
- Coding
A judgment on part of the observers by clearly defining a set of target behaviours.
- Cohen’s κ
A statistic, analogous to Cronbach’s α, which assess interrater reliability.
- Cohen’s d
The most widely used measure of effect size for differences between group or condition means; the difference between the two means divided by the standard deviation.
- Conceptual Definition
A definition of a psychological construct that describes the behaviours and internal processes of that construct and how it relates to other variables.
- Concern for Welfare
A guideline for the Tri-Council Policy that refers to ensuring participants are not exposed to unnecessary risk, maintaining privacy and confidentiality, and providing information to participants.
- Concurrent Validity
When the criterion is measured at the same time as the construct.
- Conditions
The different levels of the independent variable.
- Confederate
A helper of a researcher who pretends to be a real participant.
- Confidence interval
A range of values that is computed in such a way that some percentage of the time, the population parameter will lie within that range.
- Confidentiality
An agreement not to disclose participants’ personal information without their consent or some appropriate legal authorization.
- Confirmation Bias
The focus on cases that confirm beliefs and dismissal of cases that disprove them.
- Confounding Variable
An extraneous variable that differs on average across levels of the independent variable.
- Consent Form
A document informing participants of procedure, risks, and benefits of the research that is signed during the process of informed consent.
- Construct Validity
The quality of the experiment’s manipulations.
- Constructs
Variables that are not straightforward or simple to measure such as intelligence.
- Content Analysis
A family of systematic approaches to measurement using complex archival data.
- Content Validity
The extent to which a measure “covers” the construct of interest.
- Context Effect
Being tested in one condition can also change how participants perceive stimuli or interpret their task in later conditions.
- Control
Method of holding extraneous variables at a constant.
- Control Condition
A condition in a study that the other condition is compared to. This group does not receive the treatment or intervention that the other conditions do.
- convergent validity
When new measures positively correlate with existing measures of the same constructs.
- Converging Operations
Multiple operational definitions of the same construct.
- Copy Manuscripts
Manuscripts that will be submitted to a professional journal for publication.
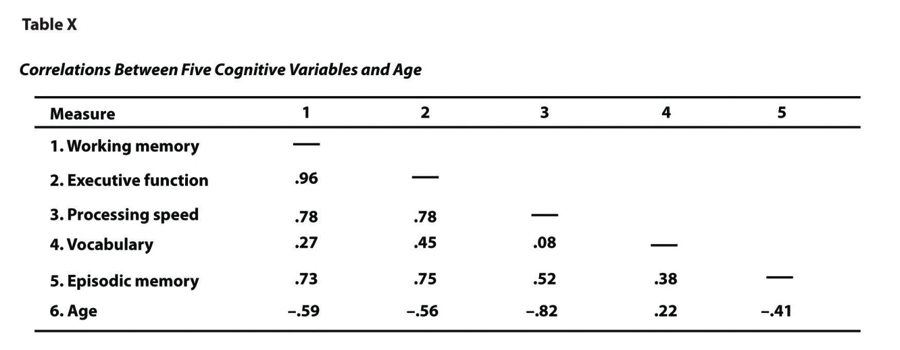
- Correlation Matrix
A table showing the correlation between every possible pair of variables in the study.
- Correlational Research
The researcher measures the two variables of interest with little or no attempt to control extraneous variables and then assesses the relationship between them.
- Counterbalancing
Testing different participants in different orders.
- Criteria
In reference to criterion validity, variables that one would expect to be correlated with the measure.
- Criterion Validity
The extent to which people’s scores on a measure are correlated with other variables that one would expect them to be correlated with.
- Critical Values
Points on the test distribution that are compared to the test statistic to determine whether to reject the null hypothesis.
- Cronbach’s α
A statistic in which α is the mean of all possible split-half correlations for a set of items.
- Data File
A record of the data collected for a research study, usually in the form of a spreadsheet.
- Debriefing
The process of informing research participants as soon as possible of the purpose of the study, revealing deception, and correcting misconceptions they may have as a result of participating in the study.
- Deception
Includes misinforming participants of the purpose of the study, using confederates, using fake equipment, or presenting false performance feedback.
- Declaration of Helsinki
An ethics code that was created by the World Medical Council in 1964, adding that research with human participants should be based on a written protocol.
- Demand Characteristics
Cues to how the researcher expects participants to behave.
- Dependent Variable (Y)
The variable that is thought to be the effect of the independent variable.
- Dependent-samples T Test
Statistical test used to compare two means for the same sample tested at two different times or under two different conditions.
- Descriptive Statistics
A set of techniques for summarizing and displaying data.
- Difference Score
Variable formed by subtracting one variable from another.
- Directionality Problem
Two variables can be statistically related because X causes Y or Y causes X.
- Discriminant Validity
The extent to which scores on a measure are not correlated with measures of variables that are conceptually distinct.
- discussion
Section of a research report that summarizes the study's results and interprets them by referring back to the study's theoretical background.
- Distribution
The way the scores are dispersed across the levels of the variable.
- Doctor of Philosophy (PhD)
A doctoral degree generally held by people who conduct scientific research in psychology.
- Double-blind Study
An experiment in which both the participants and the experimenters are blind to which condition the participants have been assigned to.
- Edited Volumes
A type of scholarly book in which an editor or small group of editors recruit many authors to write separate chapters on different aspects of the same topic.
- Effect Size
The strength of a statistical relationship.
- Empirical Questions
The second fundamental feature of science; questions about the way the world actually is and can be answered through systematic empiricism.
- Empirical Research Reports
A type of research article which describes one or more new empirical studies conducted by the authors.
- Empirically Supported Treatments
Treatments that have been shown to work through systematic observation.
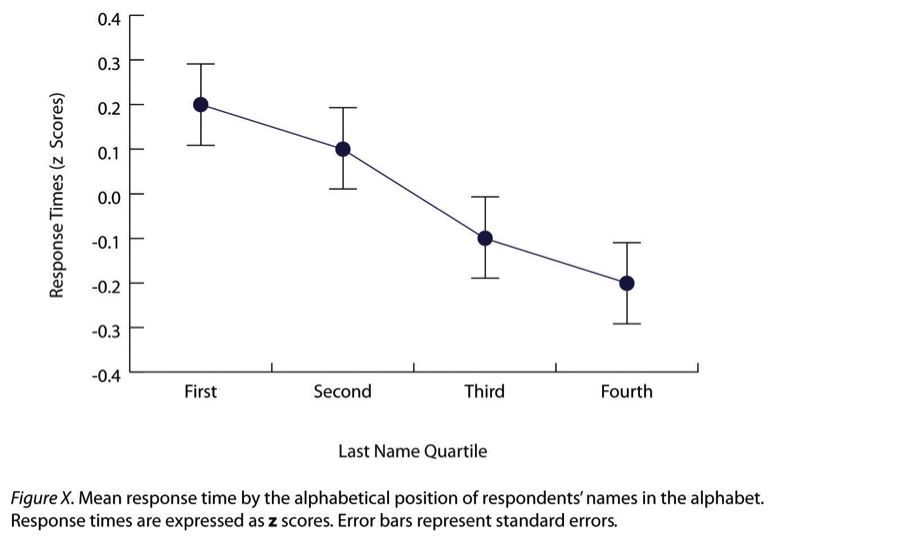
- Error Bars
Small bars at the top of each main bar in a bar graph that represent the variability in each group or condition.
- Ethics
A branch of philosophy that is concerned with morality, what it means to behave morally and how people can achieve this goal.
- Experiment
A study in which the researcher manipulates the independent variable.
- Experimental Analysis of Behaviour
Laboratory methods that rely on single-subject research; based upon B. F. Skinner’s philosophy of behaviourism which posits that everything organisms do is behaviour.
- Experimenter Expectancy Effect
A source of variation in which the experimenter’s expectations about how participants “should” be have in the experiment.
- External Validity
When the way a study is conducted supports generalizing the results to people and situations beyond those actually studied.
Anything that varies in the context of a study other than the independent and dependent variables.
- Face Validity
The extent to which a measurement method appears to measure the construct of interest.
- Factor
In a factorial design, each level of one independent variable.
- Factor Analysis
A statistical technique that organizes the variables into a smaller number of clusters, such that they are strongly correlated within each cluster but weakly correlated between clusters.
- Factorial ANOVA
A null hypothesis test that is used when more than one independent variable is included in a factorial design.
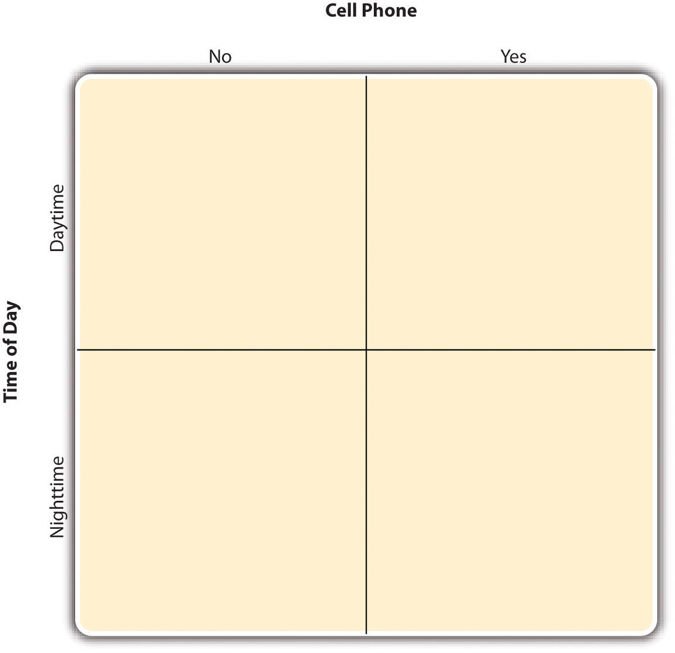
- Factorial Design
An approach to including multiple independent variables in an experiment where each level of one independent variable is combined with each level of the others to produce all possible combinations.
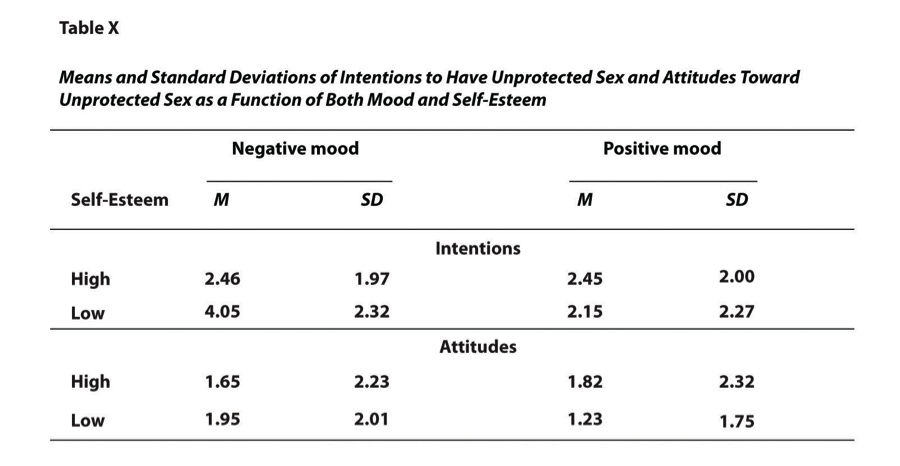
- Factorial Design Table
A table showing each condition produced by the combinations of variables.
- Falsifiable
Scientific claims must be expressed in such a way that there are observations that would count as evidence against the claim.
- Fatigue Effect
Participants perform a task worse in later conditions because they become tired or bored.
- Feasibility
the state or ability of being easily or conveniently completed.
- Field Experiments
Experiments conducted entirely outside the laboratory.
- File Drawer Problem
When researchers obtain nonsignificant results, they tend not to submit them for publication or, if they are submitted, they are not accepted.
- Final Manuscripts
Manuscripts prepared by the author in their final form with no intention of submitting them for publication elsewhere such as dissertations, theses, and other student papers.
- Focus Groups
Small groups of people who participate together in interviews focused on a particular topic or issue.
- Folk Psychology
Intuitive beliefs about people’s behaviour, thoughts, and feelings.
- Formality
The extent to which the components of the theory and the relationships among them are specified clearly and in detail.
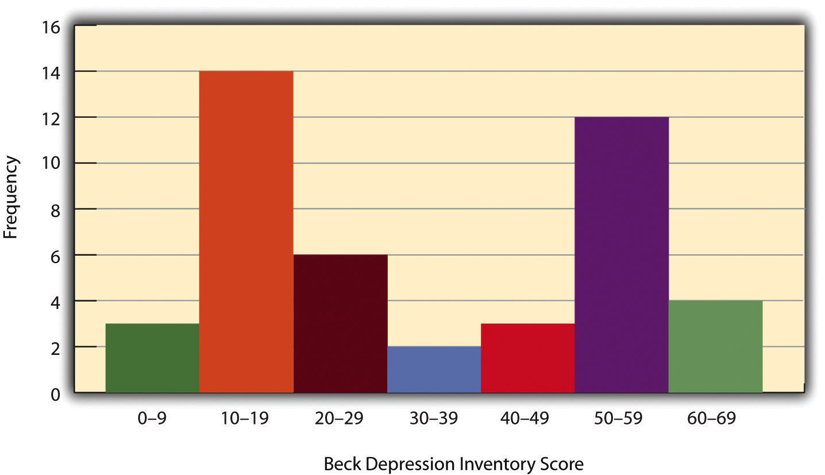
- Frequency Table
A table in which one column lists the values of a variable (the possible scores) and the other column lists the frequency of each score (how many participants had that score).
- Full REB Review
The default requirement for research involving humans.
- Functional Approach
Psychological phenomena are explained in terms of their function or purpose.
- Fundamental attribution error
People tend to explain others’ behaviour in terms of their personal characteristics as opposed to the situation they are in.
- Grounded Theory
Researchers start with the data and develop a theory or interpretation that is “grounded in” the data.
- Group Research
The study of large numbers of participants and examining their behaviour primarily in terms of group means, standard deviations, and so on.
- HARKing
Hypothesizing after the results are known.
- High-level Style
The second level of APA style which includes guidelines for the clear expression of ideas through writing style.
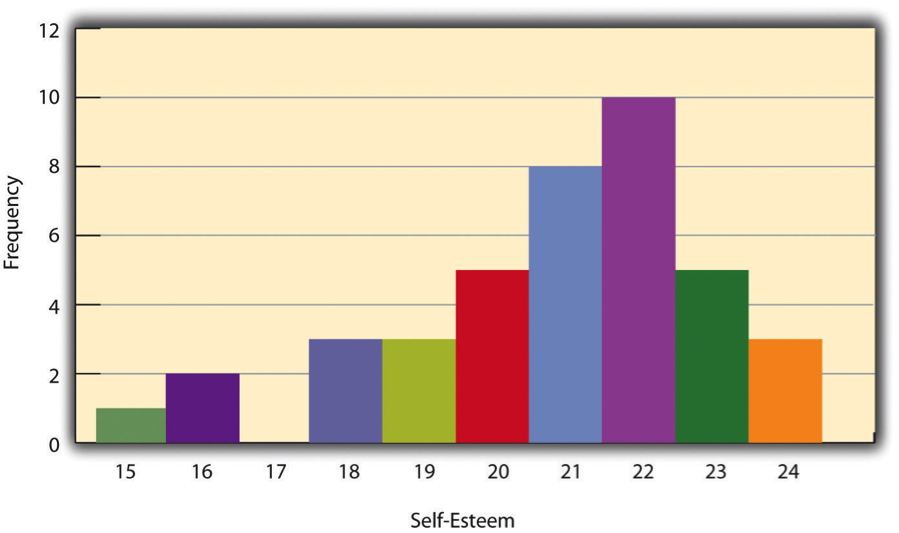
- Histogram
A graphical display of a distribution.
- History
A category of alternative explanations for differences between scores such as events that happened between the pretest and posttest, unrelated to the study.
- Hypothesis
A prediction about a new phenomenon based on a theory; can also be an explanation that relies on just a few key concepts.
- Hypothetico-deductive method
Primary way that scientific researchers use theories.
- Independent Variable (X)
The variable of a statistical relationship that is thought to cause the other variable.
- Independent-samples T Test
Statistical test used to compare the means of two separate samples.
- Informed Consent
Researchers obtain and document people’s agreement to participate in a study after having informed them of everything that might reasonably be expected to affect their decision.
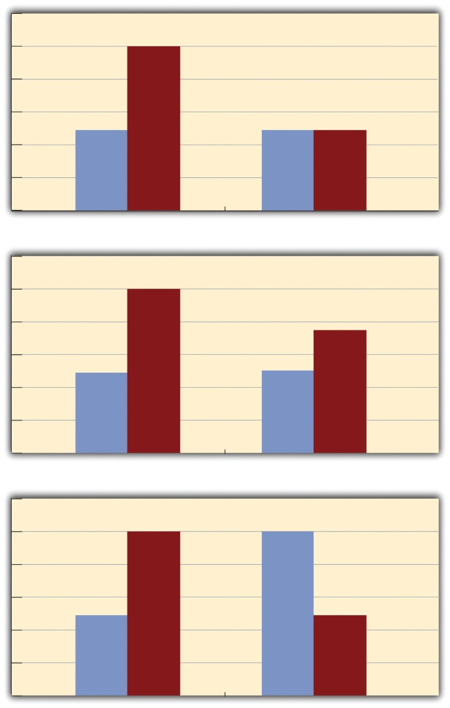
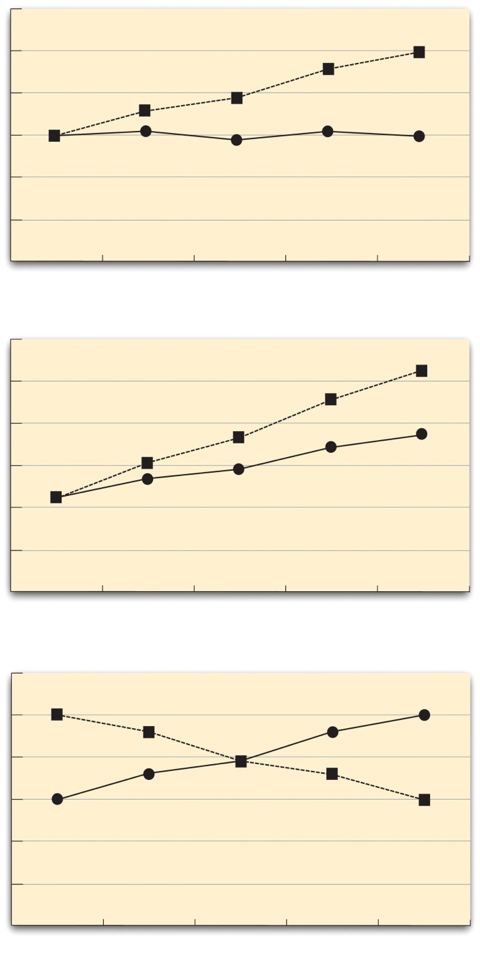
- Interaction
When the effect of one independent variable depends on the level of another.
- Interestingness
The level a research question is interesting to the scientific community and people in general.
- Internal Consistency
Consistency of people’s responses across the items on a multiple-item measure.
- Internal Validity
When the way an experiment was conducted supports the conclusion that the independent variable caused observed differences in the dependent variable. These studies provide strong support for causal conclusions.
- Interrater Reliability
The extent to which different observers are consistent in their judgments.
- Interrupted Time-series Design
A set of measurements taken at intervals over a period of time that are interrupted by a treatment.
- Interval Level
Level of measurement in which scores represent the precise magnitude of the difference between individuals, but a score of 0 does not represent an absence of the characteristic.
- Interviews
A way to collect qualitative data consisting of both general questions and more detailed questions.
- Introduction
The third page of a manuscript containing the research question, the literature review, and comments about how to answer the research question.
- Item-order Effect
The order in which the items are presented affects people’s responses.
- Justice
A guideline of the Tri-Council Policy that refers to the obligation to treat people fairly and equitably.
- Latency
The time it takes for the dependent variable to begin changing after a change in conditions.
- Level
Whether the data is higher or lower based on a visual inspection of the data; a change in the level implies the treatment introduced had an effect.
- Levels of Measurement
Different levels of quantitative information that can be communicated by a set of scores.
- Line Graphs
A graph used to present correlations between quantitative variables when the independent variable has, or is organized into, a relatively small number of distinct levels.
- Literature Review
A description of relevant previous research on the topic being discusses and an argument for why the research is worth addressing.
- Low-level style
Third level of APA style which includes all the specific guidelines pertaining to spelling, grammar, references and reference citations, numbers and statistic, figures and tables, and so on.
- Main Effect
In factorial design, the statistical relationship between one independent variable and a dependent variable--averaging across the levels of the other independent variable.
- Manipulate
To change an independent variable’s level systematically so that different groups of participants are exposed to different levels of that variable, or the same group of participants is exposed to different levels at different times.
- Manipulation Check
A separate measure of the construct the researcher is trying to manipulate.
- Maturation
An alternative explanation that refers to how the participants might have changed between the pretest and posttest in ways that they were going to anyway because they are growing and learning.
- McGurk effect
When audio of a basic speech sound is combined with video of a person making mouth movements for a different speech sound, people often perceive a sound that is intermediate between the two.
- Mean
Symbolized M, the sum of the scores divided by the number of scores.
- Mean Squares Between Groups (MSB)
An estimate of population variance based on the differences among the sample means.
- Mean Squares Within Groups (MSW)
An estimate of population variance based on the differences among the scores within each group.
- Measurement
The assignment of scores to individuals where the scores represent some characteristic of the individuals.
- Mechanistic Theories
Focus on specific variables, structures, and processes as well as how these factors interact to produce a particular phenomena.
- Median
The middle score in the sense that half the scores in the distribution are less than it and half are greater than it.
- Mere exposure effect
The more often people have been exposed to a stimulus, the more they like it—even when the stimulus is presented subliminally.
- method section
The section of a research report where the method used to conduct the study is described.
- Minimal Risk Research
When the likelihood and magnitude of possible harms faced by the participants is no greater than those encountered in in everyday life.
- Mixed Factorial Design
When one independent variable is manipulated between subjects and another is manipulated within subjects.
- Mixed-methods Research
The combination of quantitative and qualitative research.
- Mode
The most frequent score in a distribution.
- Model
A precise explanation or interpretation of a specific phenomenon; expressed in terms of equations, computer programs, or biological structures and processes.
- Monograph
Type of scholarly book written by a single author or small group of authors, coherently presents a topic much like an extended review article.
- Multiple Dependent Variables
When researchers examine the relationship between a single independent variable and more than one dependent variable.
- Multiple Regression
Measuring several independent variables, all of which are possible causes of a single dependent variable. This results in an equation that expresses the dependent variable as an additive combination of the independent variables.
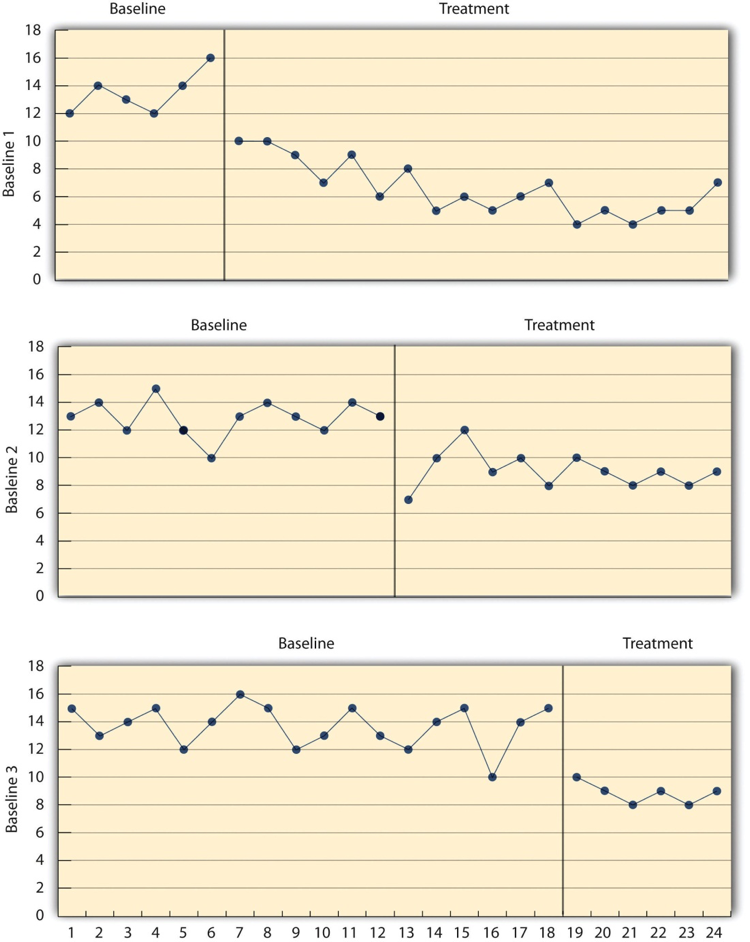
- Multiple-baseline Design
A baseline is established for several participants and the treatment is then introduced to each participant at a different time.
- Multiple-treatment Reversal Design
A baseline phase is followed by separate phases in which different treatments are introduced.
- Mundane Realism
The participants and the situation studied are similar to those that the researchers want to generalize to and participants encounter everyday.
- Naturalistic Observation
An approach to data collection that involves observing people’s behaviour in the environment in which it typically occurs.
- Negative Relationship
Higher scores on one variable tend to be associated with lower scores on the other variable.
- No-Treatment Control Condition
A type of control condition in which participants receive no treatment.
- Nominal Level
Level of measurement used for categorical variables and involves assigning scores that act as category labels.
- Nonequivalent Groups Design
A between-subjects design in which participants have not been randomly assigned to conditions.
- Nonexperimental Research
Research that lacks the manipulation of an independent variable, random assignment of participants to conditions or orders of conditions, or both.
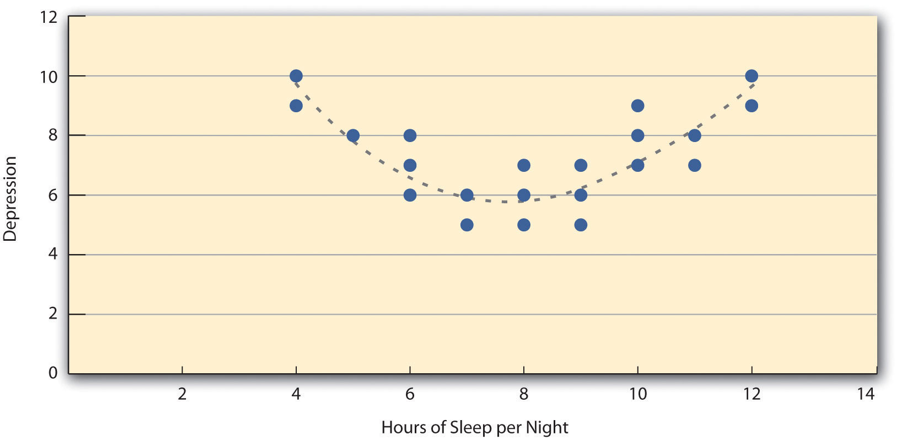
- Nonlinear Relationships
The points of a data set are better fit by a curved line.
- Nonmanipulated Independent Variable
In a factorial design, the researcher measures an independent variable but does not manipulate it.
- Nonprobability Sampling
When the researcher cannot specify the probability that each member of the population will be selected for the sample.
- Nonresponse Bias
A form of sampling bias in which survey nonresponders differ from responders in systematic ways.
- Null Hypothesis
The idea that there is no relationship in the population and that the relationship in the sample reflects only sampling error.
- Null Hypothesis Testing
A formal approach to deciding between two interpretations of a statistical relationship in a sample.
- Nuremberg Code
A set of ten principles written in 1947 in conjunction with the trials of Nazi physicians that provided a standard by which to compare the behaviour of the men on trial.
- Occam's razor
Another term for parsimony (see definition for parsimony).
- One-Sample T Test
Compares a sample mean with a hypothetical population mean that provides some interesting standard of comparison.
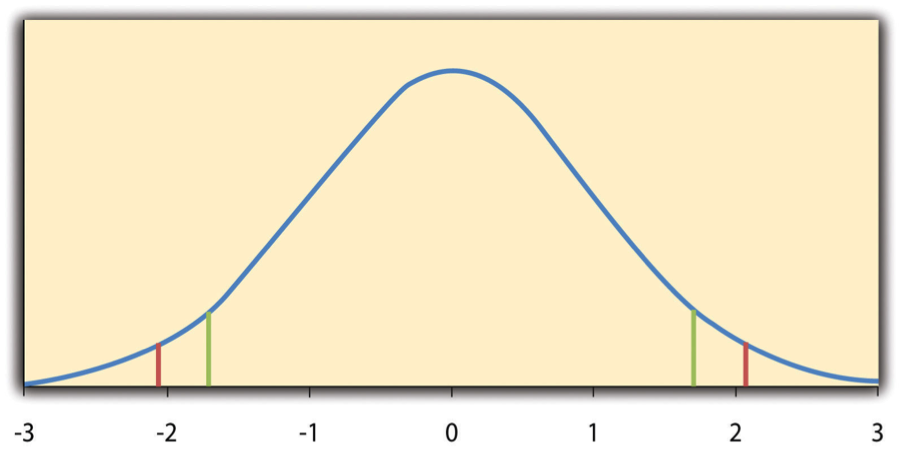
- One-tailed Test
Where the null hypothesis is rejected only if the t score for the sample is extreme in one direction that we specify before collecting the data.
- One-Way ANOVA
A null hypothesis test that is used for between-between subjects designs with a single independent variable.
- Open Science Practices
Practices that increase the transparency and openness of the scientific enterprise. Examples include the pre-registration of hypotheses and the sharing of raw data and research materials.
- Open-ended items
A questionnaire item that allows participants to answer in whatever way they choose.
- Opening
An introduction to the research question and explanation for why this question is interesting.
- Operational Definition
A definition of the variable in terms of precisely how it is to be measured.
- Operationalization
Conversion from research question to experiment design.
- Oral Presentations
Also known as a “talk”, presenters stand in front of an audience of other researchers and explains their research, usually assisted by a slide show.
- Ordinal Level
Level of measurement in which scores represent the rank order of the individuals, showing how individuals are different from each other and whether they are higher or lower on the variable being measured.
- Organization
Referring to an article, the sections that are included and what order they appear in.
- Other-race effect
People recognize faces of people of their own race more accurately than faces of people of other races.
- Outlier
An extreme score that is much higher or lower than the rest of the scores in the distribution.
- P Hacking
A data malpractice in which a researcher might perform inferential statistical calculations to see if a result was significant before deciding whether to recruit additional participants and collect more data.
- P Value
The probability that, if the null hypothesis were true, the result found in the sample would occur.
- Parameters
Values in a population that correspond to variables measured in a study.
- Parsimony
A principle which holds that a theory should include only as many concepts as are necessary to explain or interpret the phenomena of interest.
- Participant Observation
Researchers become active participants in the group or situation they are studying.
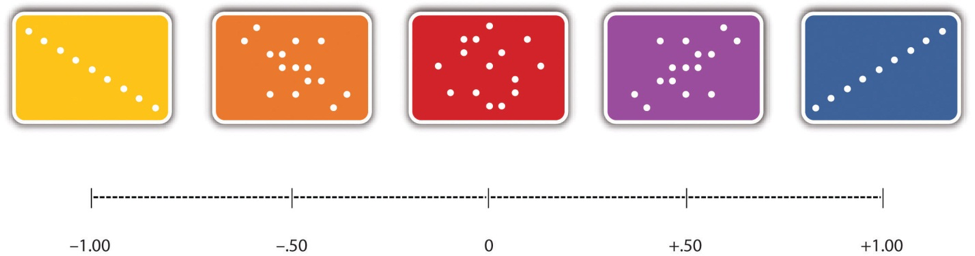
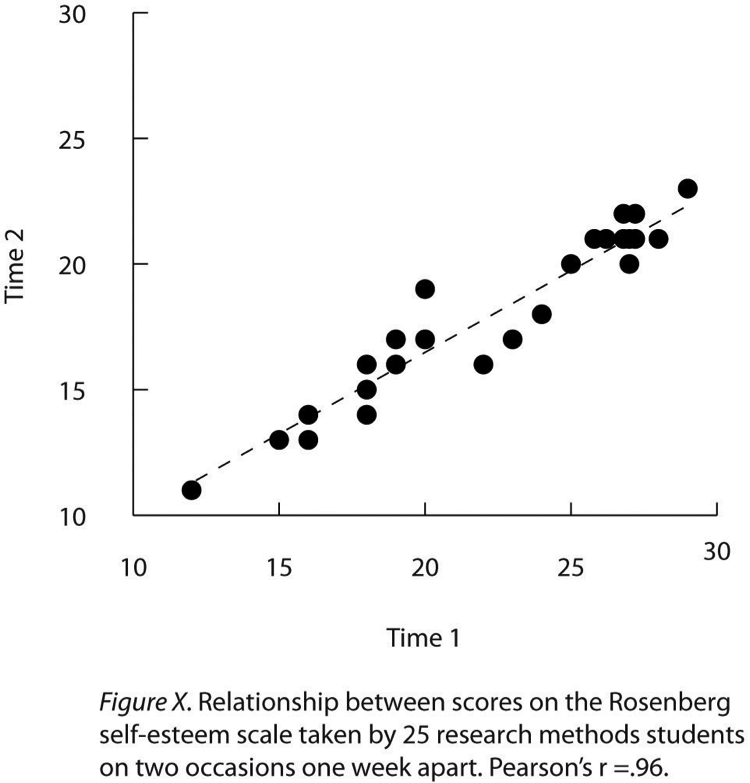
- Pearson’s r
A statistic measuring the strength of a correlation between quantitative variables ranging from -1.00 (strongest negative relationship) to +1.00 (strongest positive relationship), with 0 showing no relationship between variables.
- Peer Review
A process in which articles are reviewed by two or three experts on the article topic in order to ensure the work meets basic standards of the field before it can enter the research literature.
- Percentage of Nonoverlapping Data (PND)
The percentage of responses in the treatment condition that are more extreme than the most extreme response in a relevant control condition.
- Percentile Rank
The percentage of scores in the distribution that are lower than a particular score.
- perspective
A broad approach to explaining and interpreting phenomena.
- Phenomenon
A general result that has been observed reliably in systematic empirical research.
- Pilot Test
A small-scale study conducted to make sure that a new procedure works as planned.
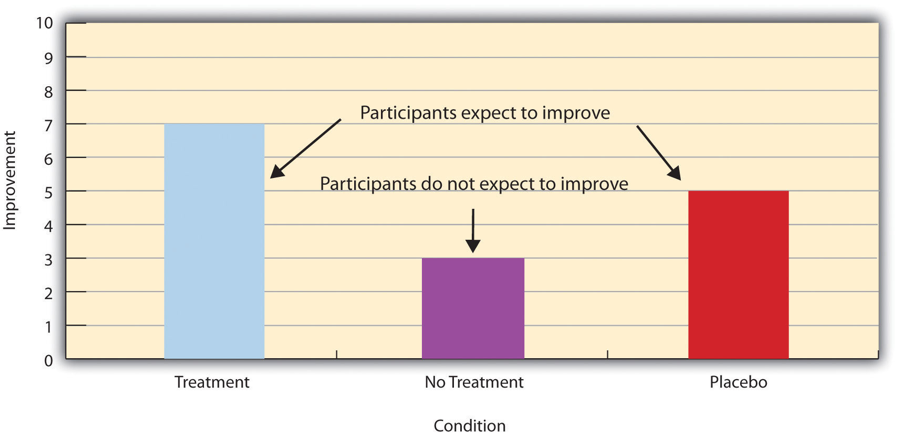
- Placebo
A simulated treatment that lacks any active ingredient or element that should make it effective.
- Placebo Control Condition
Participants receive a placebo that looks like the treatment but lacks the active ingredient or element thought to be responsible for the treatment’s effectiveness.
- Placebo Effect
A positive effect of a treatment that lacks any active ingredient or element to make it effective.
- Population
A very large group of people.
- Positive Relationship
Higher scores on one variable tend to be associated with higher scores on the other variable.
- Post Hoc Comparisons
Analysis of selected pairs of group means to determine which are different from which others.
- Poster Session
A type of conference presentation in which posters are set up on bulletin boards arranged around a large room where other researchers may circulate through the room, examine the posters, and speak with the presenters.
- Practical Significance
The importance or usefulness of the result in some real-world context.
- Practice Effect
Participants perform a task better in later conditions because they have had a chance to practice it.
- Predictive Validity
when the criterion is measured at some point in the future (after the construct has been measured).
- Prescreening
A procedure used to identify and eliminate participants who are at high risk.
- Pretest-posttest Design
The dependent variable is measured once before the treatment is implemented and once after it is implemented.
- Privacy
A person’s right to decide what information about them is shared with others.
- Probability Sampling
The researcher can specify the probability that each member of the population will be selected for the sample.
- Professional Conferences
Method for researchers to share their work with other researchers through presentations such as “talks” or posters.
- Professional Journals
Periodicals that publish original research articles.
- Prospect Theory
A formal theory of decision making under uncertainty.
- Protocol
A detailed description of the research that is reviewed by an independent committee.
- Pseudoscience
Activities and beliefs that are claimed to be scientific by their proponents, and may appear scientific, but are not.
- Psychological Realism
The same mental process is used in both the laboratory and in the real world.
- Psychometrics
Measurement used in the field of psychology.
- PsycINFO
An electronic database covering thousands of professional journals and scholarly books produced by the APA.
- Public Knowledge
The third fundamental feature of science; scientists publish their work after asking empirical questions, making systematic observations, and drawing conclusions.
- Publication Manual of the American Psychological Association
A book produced by the APA containing standards for preparing manuscripts to be submitted for publication in order to facilitate scientific communication by promoting clarity of expression and standardizing the organization and content of articles and book chapters.
- Qualitative Research
Research where the data are usually non-numerical and are analysed using non-statistical techniques.
- Quantitative Research
Research in which data is gathered from a large number of individuals and described using a statistical technique.
- Quantitative Variable
A quantity that is typically measured by assigning a number to each individual.
- Quasi-experimental Research
The researcher manipulates an independent variable but does not randomly assign participants to conditions or orders of conditions.
- Random Assignment
A method of controlling extraneous variables across conditions by using a random process to decide which participants will be tested in the different conditions.
- Randomized Clinical Trial
A type of experiment to research the effectiveness of psychotherapies and medical treatments.
- Range
The difference between the highest and lowest scores in the distribution.
- Rating Scale
An ordered set of responses that participants must choose from.
- Ratio Level
Level of measurement in which there is a true zero point that represents the complete absence of the characteristic.
- Raw Data
Unanalysed data collected for a research study.
- Reactivity
A phenomenon which occurs when subjects alter their performance due to their awareness of being observed.
- Reference Citation
The referral to another researcher’s idea that is written in the text, with the full reference appearing in the reference list.
- References
The source of information used in a research article.
- Regression To The Mean
The statistical fact that an individual who scores extremely on a variable on one occasion will tend to score less extremely on the next occasion.
- Reject the Null Hypothesis
When the relationship found in the sample would be extremely unlikely, the idea that the relationship occurred “by chance” is rejected.
- Reliability
The consistency of a measure.
- Repeated-Measures ANOVA
The dependent variable is measured multiple times for each participant, allowing a more refined measure of MSW.
- Replicability Crisis
The inability of researchers to replicate earlier research findings.
- Replication
Conducting a study again, either exactly as was originally conducted or with modifications, to ensure that it will produce the same results.
- Rescorla-Wagner model
A theory of classical conditioning that features an equation describing how the strength of the association between unconditioned and conditioned stimuli changes when the two are paired.
- Research Ethics Board (REB)
A committee that is responsible for reviewing research protocols for potential ethical problems.
- Research Literature
All the published research in a particular field.
- Respect for Persons
A guideline for the Tri-Council Policy that refers to respecting the autonomy of research participants through free, informed, and ongoing consent and protection of those incapable of exercising autonomy.
- Respondents
Participants of a survey.
- Restriction of Range
One or both of the variables have a limited range in the sample relative to the population.
- Results Section
The main results of the study, including the results from statistical analyses, are presented in a research article.
- Retain the Null Hypothesis
When the relationship found in the sample is likely to have occurred by chance, the null hypothesis is not rejected.
- Reversal Design (ABA design)
A study method in which the researcher gathers data on a baseline state, introduces the treatment and continues observation until a steady state is reached, and finally removes the treatment and observes the participant until they return to a steady state.
- Review Articles
A type of research article that summarizes previously published research on a topic and usually presents new ways to organize or explain the results.
- Sample
A small subset of a population.
- Sampling Bias
When a sample is selected in such a way that it is not representative of the entire population and therefore produces inaccurate results.
- Sampling Error
The random variability in a statistic from sample to sample.
- Sampling Frame
A list of all the members of the population from which to select the respondents.
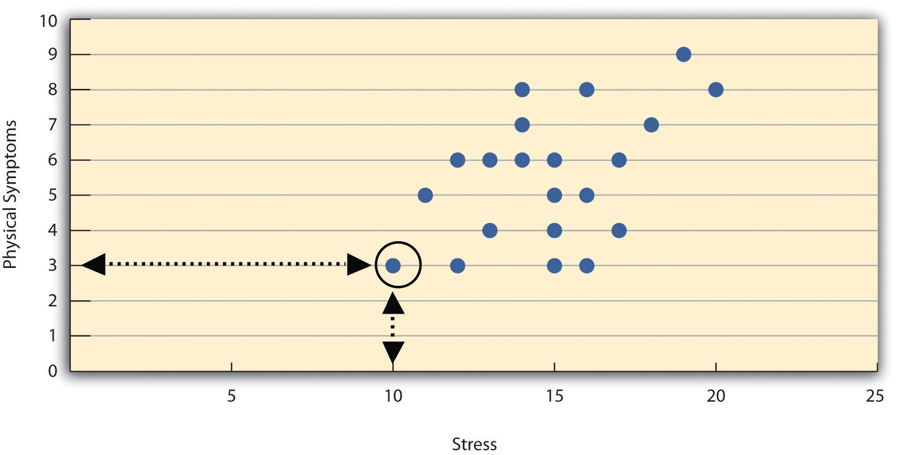
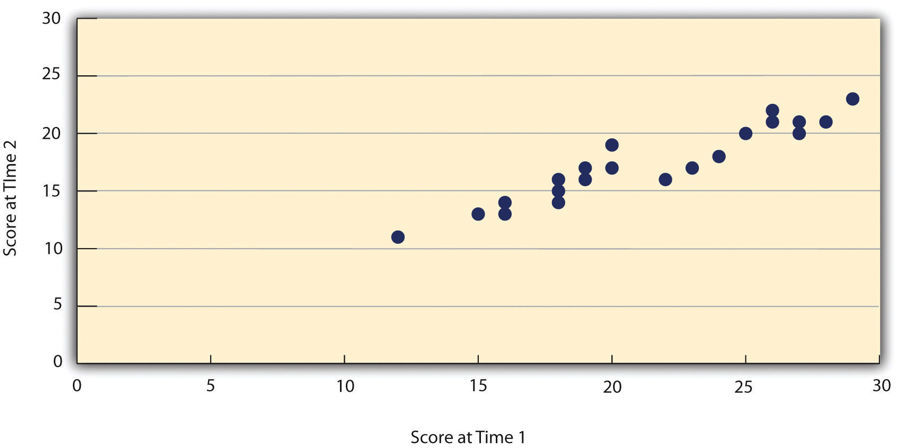
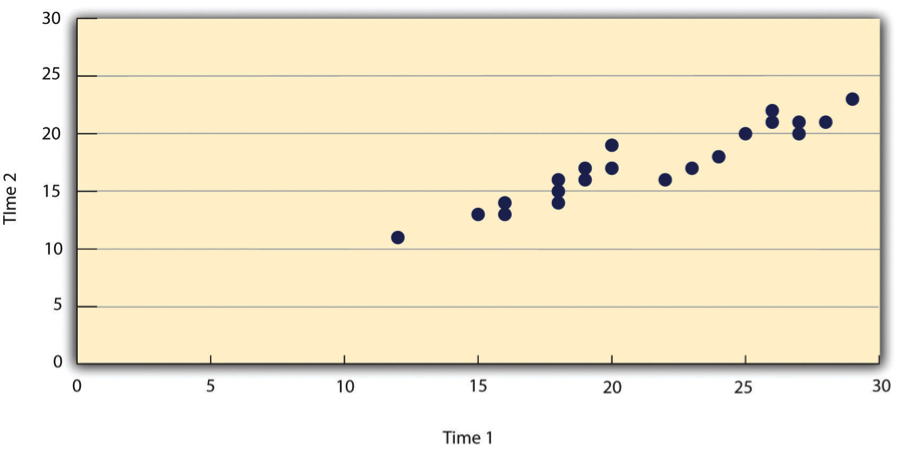
- Scatterplots
A graph which shows correlations between quantitative variables; each point represents one person’s score on both variables.
- Scholarly Books
Books written by researchers and practitioners mainly for sue by other researchers and practitioners.
- Science
A general approach to understanding the natural world.
- Scope
The number and diversity of the phenomena a theory explains or interprets.
- Self-report Measures
Measures in which participants report on their own thoughts, feelings, and actions.
- Serial position effect
Stimuli presented near the beginning and end of a list are remembered better than stimuli presented in the middle.
- Simple Random Sampling
A probability sampling method in which each individual in the population has an equal probability of being selected for the sample.
- Single-Subject Research
A type of quantitative research that involves studying the behaviour of each small number of participants in detail.
- Single-Variable Research
Research that focuses on a single variable rather than a statistical relationship between two variables.
- Skepticism
An attitude in which one considers alternatives and searches for evidence.
- Skewed
The peak of a distribution is shifted towards either the upper or lower end of its range.
- Social Validity
The study of strong and consistent effects that can be implemented reliably in the real-world contexts in which they occur.
- Socially Desirable Responding
A phenomenon where participants respond in the way they believe to be socially appropriate or in a way desired by the researcher.
- Split-half Correlation
Method of assessing internal consistency through splitting the items into two sets and examining the relationship between them.
- Spontaneous recovery
A conditioned response that has been extinguished often returns with no further training after the passage of time.
- Spontaneous Remission
The tendency for many medical and psychological problems to improve over time without any form of treatment.
- Stage Theories
Specify a series of stages that people pass through as they develop or adapt to their environment.
- Standard Deviation
The average distance between the scores and the mean.
- Standard Error
The standard deviation of the group divided by the square root of the sample size of the group.
- Statistical Control
The researcher measures potential third variables and includes them in the statistical analysis.
- Statistical Power
The probability of rejecting the null hypothesis given the sample size and expected relationship strength.
- Statistical Relationship
Occurs when the average score on one variable differs systematically across the levels of the other variable.
- Statistical Validity
Whether the statistics conducted in the study support the conclusions that are made.
- Statistically Significant
When there is less than a 5% chance of a result as extreme as the sample result occurring and the null hypothesis is rejected.
- Steady State Strategy
The researcher waits until the participant’s behaviour in one condition becomes fairly consistent from observation to observation before changing conditions. This way, any change across conditions will be easy to detect.
- Stratified Random Sampling
A method of probability sampling in which the population is divided into different subgroups or “strata” and then a random sample is taken from each “stratum.”
- Subject Pool
An established group of people who have agreed to be contacted about participating in research studies.
- Survey Research
A quantitative approach in which variables are measured using self-reports from a sample of the population.
- Symmetrical
A distribution whose left and right halves are mirror images of each other.
- Systematic Empiricism
The first fundamental feature of science; careful planning, making, recording, and analyzing observations of the natural world for the purposes of learning.
- T Test
A common null hypothesis test examining the difference between two means.
- Test Statistic
A statistic that is computed only to help find the p value.
- Test-retest Correlation
The consistency of a measure on the same group of people at different times.
- Test-retest Reliability
The consistency of a measure over time.
- Theoretical Approach
Theories in psychology are constructed from a variety of theoretical ideas.
- Theoretical Article
A type of review article primarily devoted to presenting a new theory.
- Theoretical Framework
The established context applied to understanding a phenomenon.
- Theoretical Narrative
An interpretation of the data in terms of the themes identified through qualitative research.
- Theory
A coherent explanation or interpretation of one or more phenomena.
- Third-variable Problem
Two variables may be statistically related, but both may be caused by a third and unknown variable.
- Title Page
The page at the beginning of an APA-style research report containing the title of the article, the authors’ names, and their institutional affiliation.
- Tolerance for Uncertainty
The acceptance of the unknown.
- Treatment
Any intervention meant to change people’s behaviour for the better.
- Treatment Condition
A condition in a study where participants receive treatment.
- Trend
The gradual increases or decreases in the dependent variable across observations.
- Tri-Council Policy Statement
Ethical Conduct for Research Involving Humans: Canadian code of ethics that must be followed by researchers and research institutions.
- Triangulation
Using both quantitative and qualitative methods simultaneously to study the same general questions and to compare the results.
- Two-tailed Test
The null hypothesis is rejected if the t score for the sample is extreme in either direction.
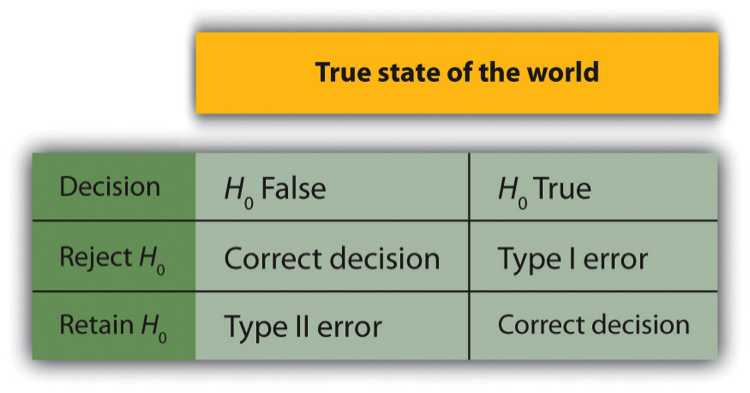
- Type I Error
When the null hypothesis is rejected when it is true; when the research concludes there is a relationship in the population when in fact there is not.
- Type II Error
When the null hypothesis is retained when it is false; when the research conclues there is no relationship in the population when in fact there is one.
- Typologies
Groups organized by the distinct type of person or behaviour being categorized.
- Validity
The extent to which the scores from a measure represent the variable they are intended to.
- Variability
The extent to which the scores vary around their central tendency.
- Variable
A quantity or quality that varies across people or situations.
- Variance
The mean of the squared differences; a measure of variability.
- Visual Inspection
The plotting of individual participants’ data, examining the data, and making judgements about whether and to what extent the independent variable had an effect on the dependent variable.
- Waitlist Control Condition
Participants are told that they will receive the treatment but must wait until the participants in the treatment condition have already received it.
- Within-subjects Experiment
Each participant is tested under all conditions.
- Z Score
The difference between an individual’s score and the mean of the distribution, divided by the standard deviation of the distribution.














")



















![\[M=\Sigma X\div N\]](https://opentextbc.ca/researchmethods/wp-content/ql-cache/quicklatex.com-c45fb186799b0902bdc046efa8e66d90_l3.svg "Rendered by QuickLaTeX.com")
![\[SD=\sqrt{\dfrac{\Sigma (X-M)^2}{N}}\]](https://opentextbc.ca/researchmethods/wp-content/ql-cache/quicklatex.com-5c10b89a2dc7455a40eaf6e74d5d4392_l3.svg "Rendered by QuickLaTeX.com")




![\[z=(X-M)\div SD\]](https://opentextbc.ca/researchmethods/wp-content/ql-cache/quicklatex.com-f38a0358f6d25e5408bd9477bb8d5265_l3.svg "Rendered by QuickLaTeX.com")
![\[d=(M_1-M_2)\div SD\]](https://opentextbc.ca/researchmethods/wp-content/ql-cache/quicklatex.com-f8c338fe76c752e532b3ca8448c35fc9_l3.svg "Rendered by QuickLaTeX.com")
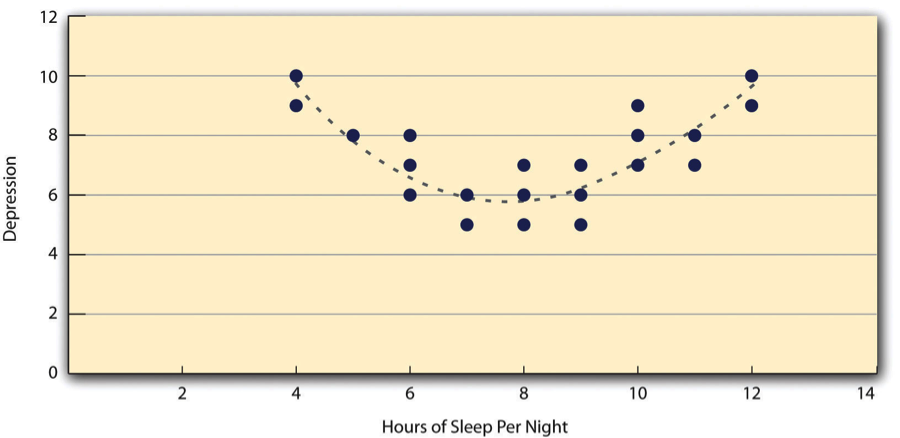
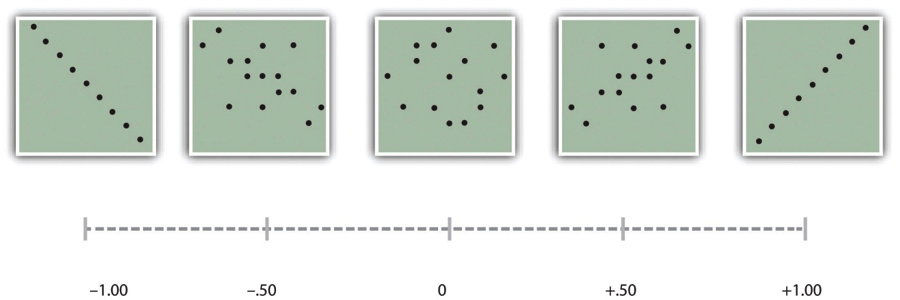
![\[r=\dfrac{\Sigma(z_xz_y)}{N}\]](https://opentextbc.ca/researchmethods/wp-content/ql-cache/quicklatex.com-1783045bf6c5ed0c8022088f07541b0b_l3.svg "Rendered by QuickLaTeX.com")





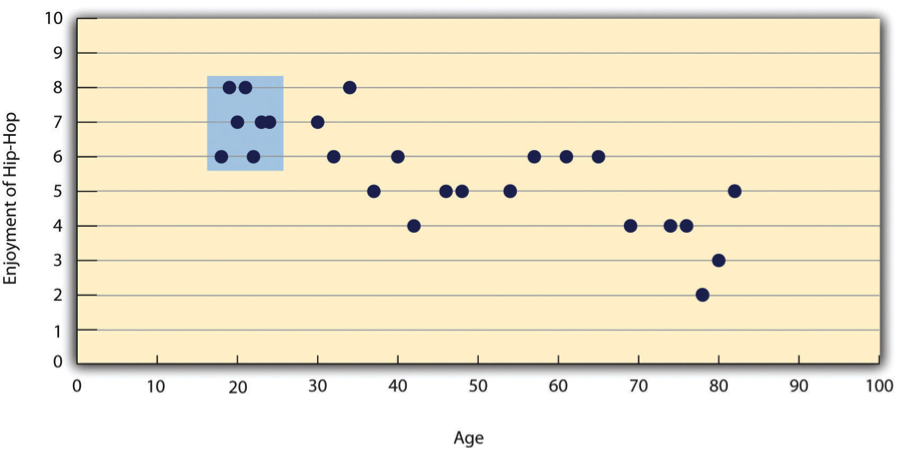


![\[t=\dfrac{M-\mu_0}{\left(\dfrac{SD}{\sqrt{N}}\right)}\]](https://opentextbc.ca/researchmethods/wp-content/ql-cache/quicklatex.com-5cabf5ed8125558a7361164aadc41c78_l3.svg "Rendered by QuickLaTeX.com")
![\[t=\dfrac{212-250}{\left(\dfrac{39.17}{\sqrt{10}}\right)}=-3.07\]](https://opentextbc.ca/researchmethods/wp-content/ql-cache/quicklatex.com-db8519a8464a24c9b7486a9cbd7fdc6b_l3.svg "Rendered by QuickLaTeX.com")
![\[t=\dfrac{8.5-0}{\left(\dfrac{27.27}{\sqrt{10}}\right)}=1.11\]](https://opentextbc.ca/researchmethods/wp-content/ql-cache/quicklatex.com-37d0f432a138ce195614d7cebaabb4d8_l3.svg "Rendered by QuickLaTeX.com")
![\[t=\dfrac{M_1-M_2}{\sqrt{\dfrac{{SD_1}^2}{n_1}+\dfrac{{SD_2}^2}{n_2}}}\]](https://opentextbc.ca/researchmethods/wp-content/ql-cache/quicklatex.com-0242d1ab42d68adb3bb852a45bfb9b2d_l3.svg "Rendered by QuickLaTeX.com")
![\[t=\dfrac{220.71-168.12}{\sqrt{\dfrac{41.23^2}{8}+\dfrac{42.66^2}{7}}}=2.42\]](https://opentextbc.ca/researchmethods/wp-content/ql-cache/quicklatex.com-8dd797ba37fac6e3618f34946daefb5b_l3.svg "Rendered by QuickLaTeX.com")




{kind=link}
{kind=link}