Chapter 10. Intelligence and Language
Communicating With Others: Development and Use of Language
Dinesh Ramoo
Approximate reading time: 70 minutes
Learning Objectives
By the end of this section, you will be able to:
- Review the components and structure of language.
- Describe the process by which people can share new information by using language.
- Characterise the typical content of conversation and its social implications.
- Characterise psychological consequences of language use and give an example.
- Describe how children acquire language.
- Describe theories of language development.
- Explain the biological underpinnings of language.
- Describe the use of language in non-human animals.
Human language is the most complex behaviour on the planet and, at least as far as we know, in the universe. Language involves both the ability to comprehend spoken and written words and to create communication in real time when we speak or write. Most languages are oral, generated through speaking. Speaking involves a variety of complex cognitive, social, and biological processes, including operation of the vocal cords and the coordination of breath with movements of the throat, mouth, and tongue.
Other languages are sign languages, in which the communication is expressed by movements of the hands. The most common sign language is American Sign Language (ASL), commonly used in many countries across the world and adapted for use in varying countries. The other main sign language used in Canada is la Langue des Signes Québécoise (LSQ); there is also a regional dialect, Maritime Sign Language (MSL).
Although language is often used for the transmission of information (e.g., “turn right at the next light and then go straight” or “place tab A into slot B”), this is only its most basic function. Language also allows us to access existing knowledge, to draw conclusions, to set and accomplish goals, and to understand and communicate complex social relationships. Language is fundamental to our ability to think; without it we would be much less intelligent than we are.
Language can be conceptualised in terms of sounds, meaning, and the environmental factors that help us understand them. Phonemes are the elementary sounds of our language; morphemes are the smallest units of meaning in a language; syntax is the set of grammatical rules that control how words are put together; and contextual information consists of the elements of communication that are not part of the content of language but that help us understand its meaning.
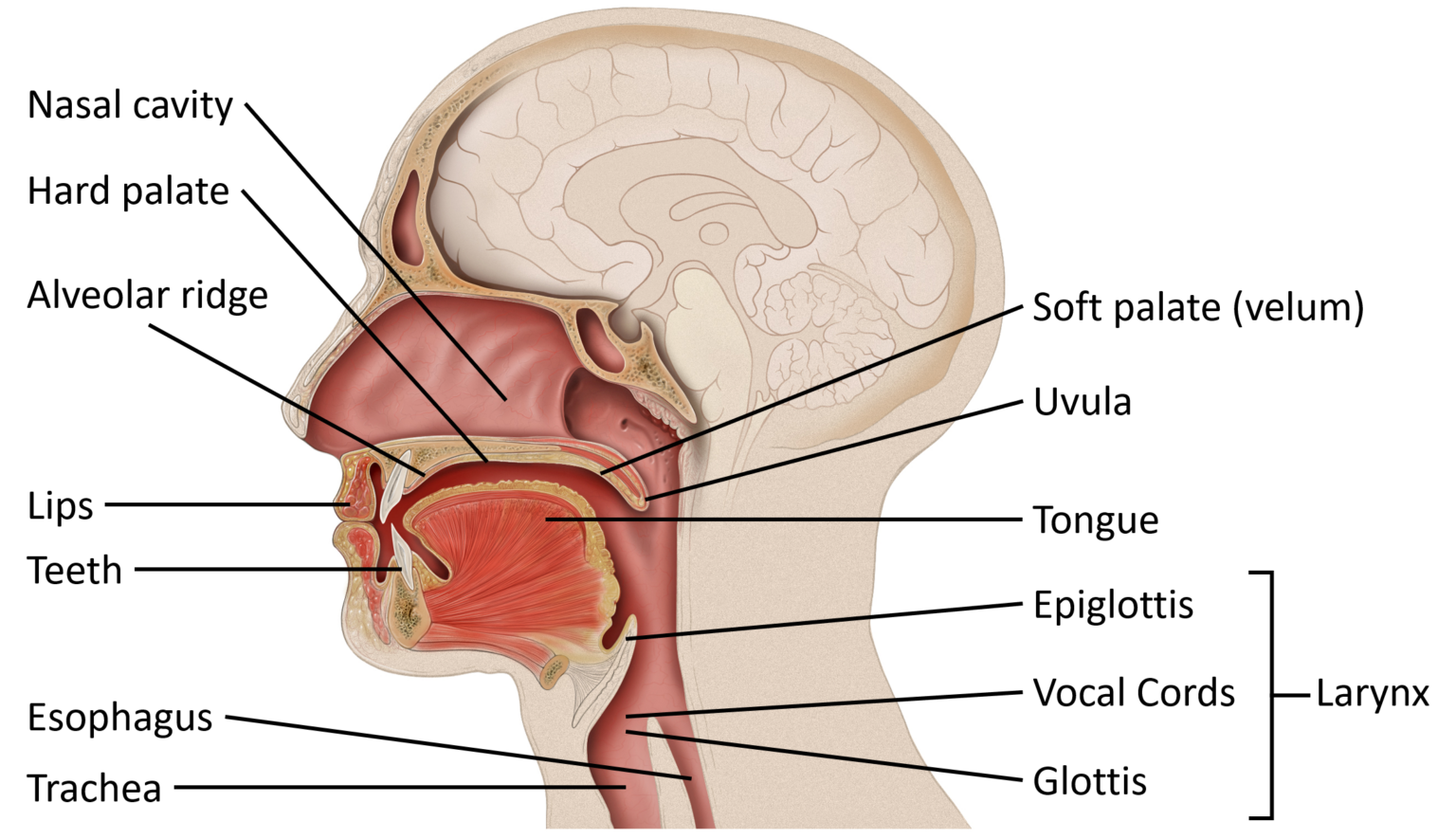
Speech requires the use of the vocal tract. The vocal tract, as seen in Figure IL.10, is composed of the parts of the mouth and nose through which air flows. The larynx provides the voice or vibration to the sounds we produce. Moving the tongue, lips, and other parts of the vocal tract modifies the airflow and allows us to produce all the sounds found in human languages.
The Components of Language
The complexity of language comes from the fact that it is made up of interconnected levels and units that interact with each other. Therefore, when you are studying language (or linguistics), you can study it at different levels depending on the context. The study of the sound patterns of language is known as phonology; the study of meaningful units is called morphology; the study of meaning is called semantics and the way language is used beyond these constraints in different contexts is known as pragmatics.
Phonology is the field of linguistics dealing with phonemes. A phoneme is the smallest unit of sound that makes a meaningful difference in a language. In transcription, phonemes are placed between slashes. For example, the word “bit” has three phonemes: /b/, /i/, and /t/. The word “pit” also has three: /p/, /i/, and /t/. The only difference between ‘pit’ and ‘bit’ is the first sound. Such words that differ in only one sound are called minimal pairs and are useful in discovering all the phonemes that exist in a language. In spoken languages, phonemes are produced by the positions and movements of the vocal tract, including our lips, teeth, tongue, vocal cords, and throat, whereas in sign languages, phonemes are defined by the shapes and movement of the hands.
Phonemes can be classified into vowels and consonants. Phonemes that are produced without any obstruction to the flow of air are called vowels. Phonemes that are produced with some kind of disruptions to the airflow are called consonants. Of course, nature is not as clear-cut as all that and we do make some sounds that are somewhere in between these two categories. These are called semivowels but are usually classified alongside consonants (e.g., initial phonemes in well and yawn).
There are hundreds of unique phonemes that can be made by human speakers, but most languages only use a small subset of the possibilities. English contains about 45 phonemes, whereas other languages have as few as 15 and others more than 60. The Hawaiian language contains only about a dozen phonemes, including five vowels — a, e, i, o, and u — and seven consonants — h, k, l, m, n, p, and w. Figure IL.11 and Figure IL.12 shows the vowels and consonants found in the English language. The outline in Figure IL.11 is called a tongue map. It shows the shape and positions of the tongue when we articulate each vowel. Each black circle is situated in the position of the tongue when that vowel is pronounced. You can check this yourself by saying ‘ee’ and ‘aa’ and feel how your tongue moves upwards for the former and downwards for the latter. Similarly try saying ‘ee’ and ‘oo’ repeatedly and feel how your tongue moved forwards for the former and backwards for the latter. Vowels are the most variable across different dialects in a language. Therefore, one of the main ways we differentiate between various dialects in a language (such as Standard Canadian, American Southern, British Received Pronunciation, or General America) is in the nature of their vowels when pronouncing the same words.
 of the tongue when producing each vowel. There are 11 vowels displayed with an example word.")
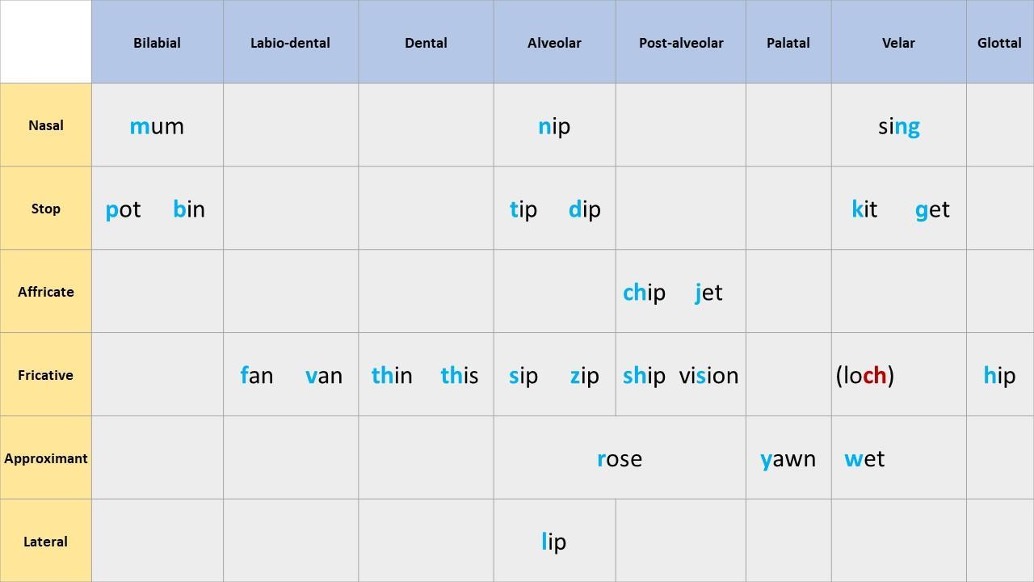
Figure IL.12 shows the consonants in English. Consonants tend to be quite stable across the various dialects of a language with some minor variations. The figure shows the consonants arranged according to their manner and place of articulation. Manner of articulation refers to how the airflow escapes through the vocal tract. For example, when you say ‘pit’ or ‘kit’ you briefly stop the airflow for the first sound in each word. Therefore, these sounds are called stops. Fricatives such as the first sounds in ‘ship’, ‘sip’, and ‘fin’ obstruct the flow of air but do not stop it. Affricates are the blend of one stop and one fricative sound. So /t/ and /sh/ together create /ch/. Nasal sounds such as /m/ and /n/ release the airflow through the nasal cavity as well as the mouth (oral cavity).
Place of articulation refers to what parts of the vocal tract come into contact when producing the consonant. Bilabial sounds such as /p/, /b/ and /m/ are produced with two (bi) lips (labia) coming into contact with each other. Dental sounds, as the name implies, are produced with the tongue touching the upper teeth. The alveolar ridge is a hard bit just behind the teeth. The tongue touching this region produces alveolar sounds such as /n/, /t/, /s/, and /l/. The going just behind the alveolar ridge (post-alveolar) produces sounds such as /sh/ as well as the ‘s’ in ‘measure’. The top of the tongue touching the top of the mouth or soft palate produces palatal sounds such as /y/ while the back of the tongue touching the velum or hard palate produces sounds such as /k/ and /g/.
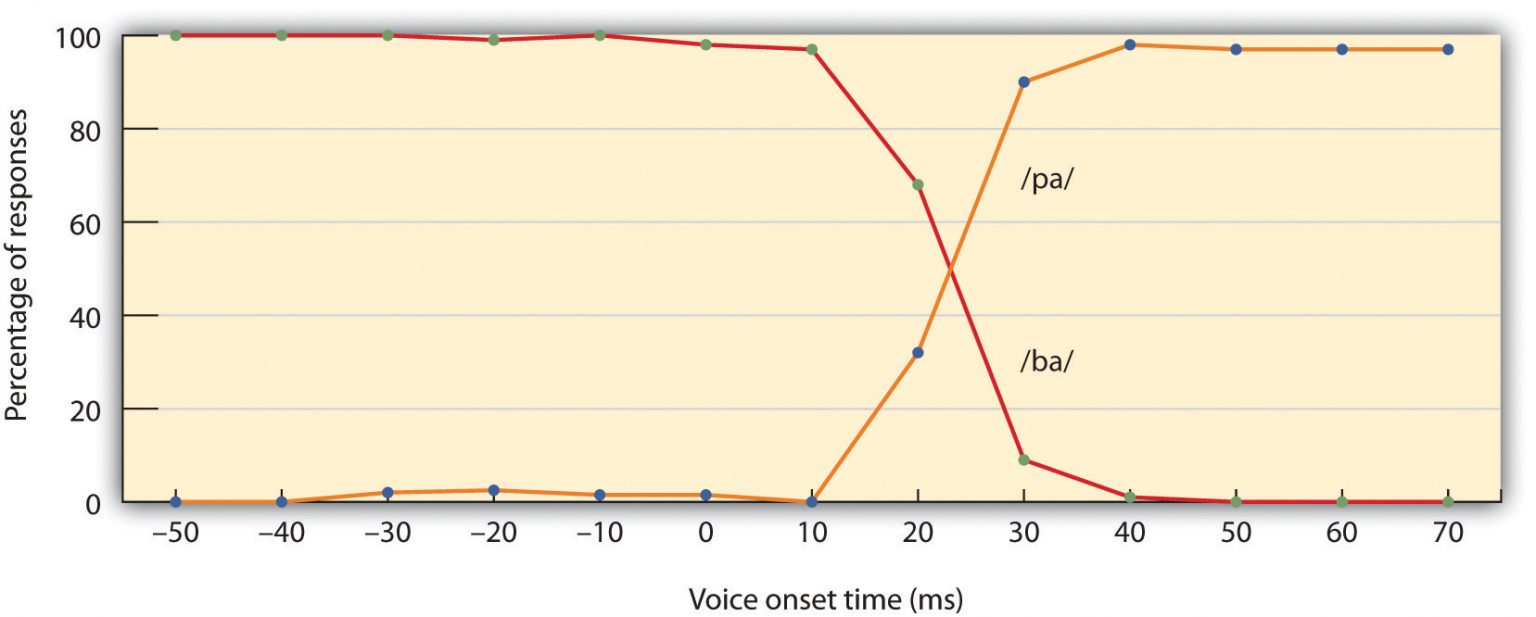
Because phonemes are actually a category of sounds that are treated alike within the language, speakers of different languages are able to hear the difference between only some phonemes but not others. This is known as the categorical perception of speech sounds. English speakers can differentiate the /r/ phoneme from the /l/ phoneme, and thus “rake” and “lake” are heard as different words. In Japanese, however, /r/ and /l/ are the same phoneme, and thus speakers of that language are not likely to tell the difference between the word “rake” and the word “lake.” Try saying the words “cool” and “keep” out loud. Can you hear the difference between the two /k/ sounds? To monolingual English speakers they both sound the same, but to speakers of Arabic, these represent two different phonemes (Figure IL.13).
Infants are born able to understand all phonemes, but they lose their ability to do so as they get older; by 10 months of age, a child’s ability to recognise phonemes becomes very similar to that of the adult speakers of the native language of the child’s culture. Phonemes that were initially differentiated come to be treated as equivalent (Werker & Tees, 2002).
Whereas phonemes are the smallest units of sound in language, a morpheme is a string of one or more phonemes that makes up the smallest units of meaning in a language. Some morphemes, such as one-letter words like “I” and “a,” are also phonemes, but most morphemes are made up of combinations of phonemes. Some morphemes are prefixes and suffixes used to modify other words. For example, the syllable “re-” as in “rewrite” or “repay” means “to do again,” and the suffix “-est” as in “happiest” or “coolest” means “to the maximum.”
Languages differ in terms of how they combine units of meaning (morphemes) to create new words. Figure IL.14 shows four types of morphology. Isolating languages do not combine morphemes but keep them isolated. Therefore, the word for an American is not a combination of ‘America’ and ‘-an’ but ‘beautiful’ ‘country’ and ‘person’. Agglutinative languages such as Salish and most Indigenous languages of Canada glue morphemes together but do not transform them. This means each morpheme is clearly observable even after combining to form a new word. On the other hand, when the fusing of morphemes leads to the resulting word changing the morpheme, this is a fusional or inflectional morphology (as seen in English or Spanish). There are some other interesting morphologies, such as Mohawk (spoken in the Eastern parts of Canada), which fuse lots of morphemes together to form extremely long words. Such polysynthetic morphologies are rare.

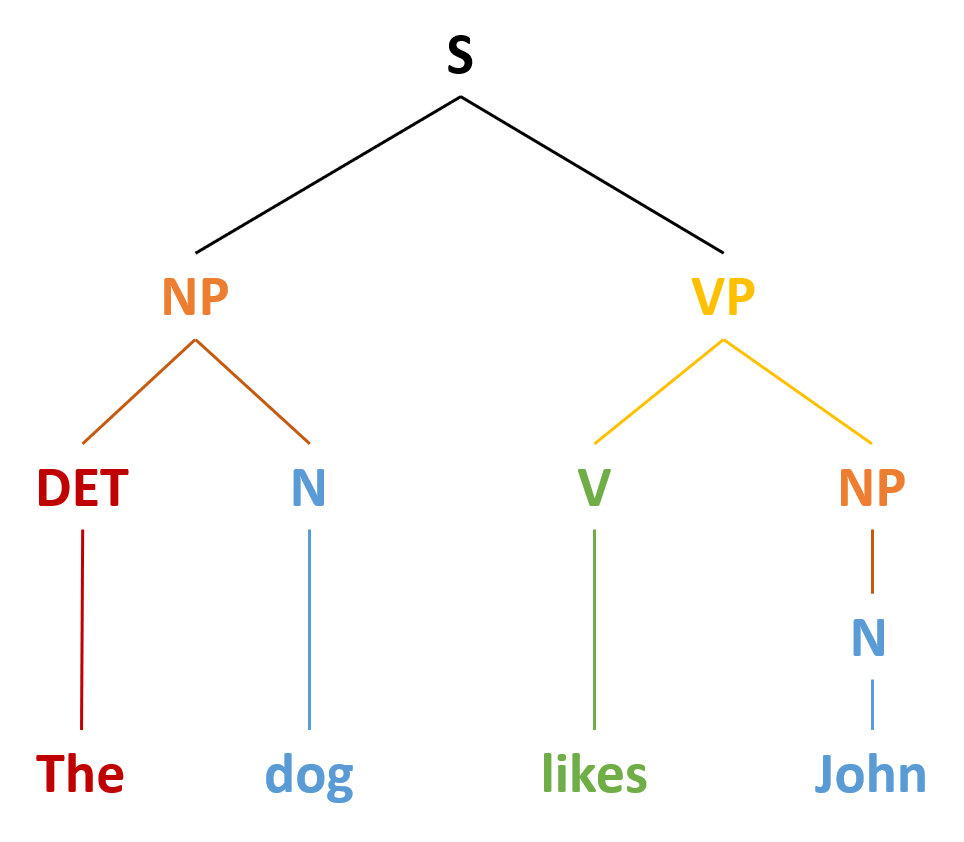
Syntax is the set of rules of a language by which we construct sentences. Each language has a different syntax. The syntax of the English language requires that each sentence have a noun and a verb, each of which may be modified by adjectives and adverbs. Figure IL.15 shows the syntax for a simple sentence in English with its syntactic categories: determiners (DET), nouns (N), verbs (V), noun phrases (NP) and verb phrases (VP). Some syntaxes make use of the order in which words appear, while others do not. In English, “The man bites the dog” is different from “The dog bites the man.” In German, however, only the article endings before the noun matter. “Der Hund beisst den Mann” means “The dog bites the man” but so does “Den Mann beisst der Hund.”
Words do not possess fixed meanings, but change their interpretation as a function of the context in which they are spoken. We use contextual information — the information surrounding language — to help us interpret it. Examples of contextual information include the knowledge that we have and that we know other people have, and nonverbal expressions such as facial expressions, postures, gestures, and tone of voice. Misunderstandings can easily arise if people are not attentive to contextual information or if some of it is missing, such as it may be in newspaper headlines or in text messages.
The following are examples of headlines in which syntax is correct, but the interpretation can be ambiguous:
- Grandmother of Eight Makes Hole in One
- “hole in one” can refer to an achievement in golf or to literally making a hole in one of the children
- Milk Drinkers Turn to Powder
- People who drink milk choose powdered milk or they literally turned to powder
- Farmer Bill Dies in House
- A government bill for farmers is voted down in the US House of Representatives or a farmer named Bill dies in a house
- Old School Pillars Are Replaced by Alumni
- The “pillars” could refer to columns or a reference to esteemed people of the school
- Two Convicts Evade Noose, Jury Hung
- “Hung” could refer to being hanged with a noose or being indecisive
- Include Your Children When Baking Cookies
- Include children in the activity of baking or literally include them as an ingredient when baking
How do we use language?
If language is so ubiquitous, how do we actually use it? To be sure, some of us use it to write diaries and poetry, but the primary form of language use is interpersonal. That’s how we learn language, and that’s how we use it. We exchange words and utterances to communicate with each other. Let’s consider the simplest case of two people, Adam and Ben, talking with each other. Judging from their clothing, they are young businessmen, taking a break from work. They have this exchange:
Adam: “You know, Gary bought a ring.”
Ben: “Oh yeah? For Mary, isn’t it?”
Adam nods.
According to Herbert Clark (1996), in order for them to carry out a conversation, they must keep track of common ground. Common ground is a set of knowledge that the speaker and listener share and they think, assume, or otherwise take for granted that they share. So, when Adam says, “Gary bought a ring,” he takes for granted that Ben knows the meaning of the words he is using, who Gary is, and what buying a ring means. When Ben says, “For Mary, isn’t it?” he takes for granted that Adam knows the meaning of these words, who Mary is, and what buying a ring for someone means. All these are part of their common ground.
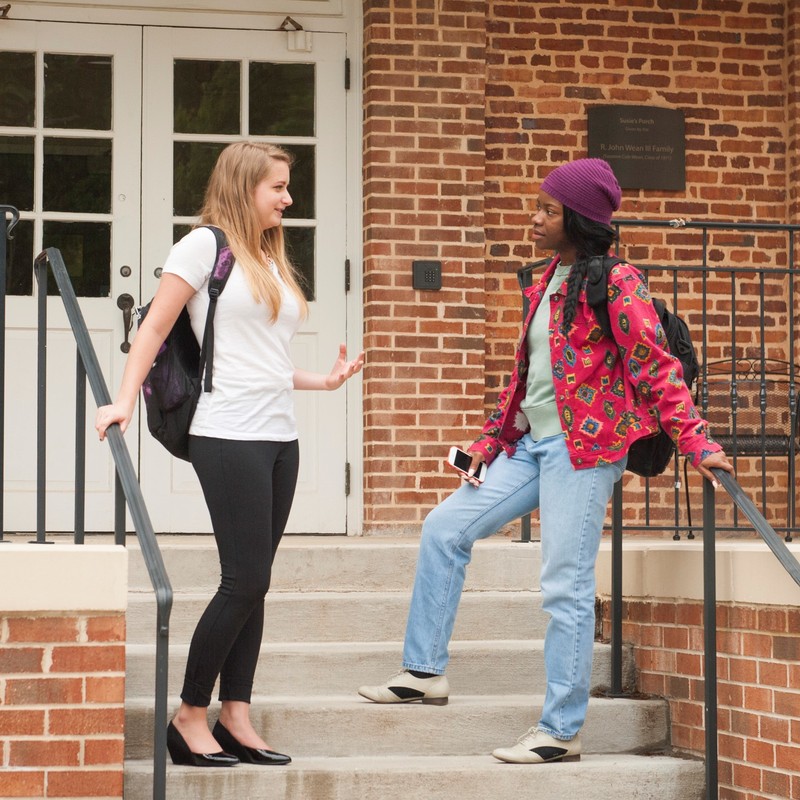
Note that, when Adam presents the information about Gary’s purchase of a ring, Ben responds by presenting his inference about who the recipient of the ring might be, namely, Mary. In conversational terms, Ben’s utterance acts as evidence for his comprehension of Adam’s utterance — “Yes, I understood that Gary bought a ring” — and Adam’s nod acts as evidence that he now has understood what Ben has said too — “Yes, I understood that you understood that Gary has bought a ring for Mary.” This new information is now added to the initial common ground. Thus, the pair of utterances by Adam and Ben, called an adjacency pair, together with Adam’s affirmative nod jointly completes one proposition, “Gary bought a ring for Mary,” and adds this information to their common ground. This way, common ground changes as we talk, gathering new information that we agree on and have evidence that we share. It evolves as people take turns to assume the roles of speaker and listener and actively engage in the exchange of meaning.
Common ground helps people coordinate their language use. For instance, when a speaker says something to a listener, they take into account their common ground, that is, what the speaker thinks the listener knows. Adam said what he did because he knew Ben would know who Gary was. He’d have said, “A friend of mine is getting married,” to another colleague who wouldn’t know Gary. This is called audience design (Fussell & Krauss, 1992); speakers design their utterances for their audiences by taking into account the audience’s knowledge. If their audience is seen to be knowledgeable about an object, such as Ben about Gary, they tend to use a brief label of the object (i.e., Gary); for a less knowledgeable audience, they use more descriptive words (e.g., “a friend of mine”) to help the audience understand their utterances.
In systematic research on audience design, Susan Fussell and Robert Krauss (1992) found that, when communicating about public figures, speakers included more descriptive information (e.g., physical appearances and occupation) about lesser known and less identifiable people (e.g., Kevin Kline or Carl Icahn) than better known ones (e.g., Woody Allen or Clint Eastwood), so that their listeners could identify them. Likewise, Ellen Isaacs and Herbert Clark (1987) showed that people who were familiar with New York City (NYC) could gauge their audience’s familiarity with NYC soon after they began conversation and adjusted their descriptions of NYC landmarks to help the audience identify such landmarks as the Brooklyn Bridge and Yankee Stadium more easily. More generally, Paul Grice (1975) suggested that speakers often follow certain rules, called conversational maxims, by trying to be informative (e.g., maxim of quantity), truthful (e.g., maxim of quality), relevant (e.g., maxim of relation), and clear and unambiguous (e.g., maxim of manner).
So, language use is a cooperative activity, but how do we coordinate our language use in a conversational setting? To be sure, we have a conversation in small groups. The number of people engaging in a conversation at a time is rarely more than four. By some counts (e.g., Dunbar, Duncan, & Nettle, 1995; James, 1953), more than 90% of conversations happen in a group of four or fewer individuals. Certainly, coordinating conversation among four is not as difficult as coordinating conversation among 10, but even among only four people, if you think about it, everyday conversation is an almost miraculous achievement. We typically have a conversation by rapidly exchanging words and utterances in real time in a noisy environment. Think about your conversation at home in the morning, at a bus stop, in a shopping mall. How can we keep track of our common ground under such circumstances?
Martin Pickering and Simon Garrod (2004) argue that we achieve our conversational coordination by virtue of our ability to interactively align each other’s actions at different levels of language use: lexicon (i.e., words and expressions), syntax (i.e., grammatical rules for arranging words and expressions together), as well as speech rate and accent. For instance, when one person uses a certain expression to refer to an object in a conversation, others tend to use the same expression (e.g., Clark & Wilkes-Gibbs, 1986). Furthermore, if someone says “the cowboy offered a banana to the robber,” rather than “the cowboy offered the robber a banana,” others are more likely to use the same syntactic structure (e.g., “the girl gave a book to the boy” rather than “the girl gave the boy a book”) even if different words are involved (Branigan, Pickering, & Cleland, 2000). Finally, people in conversation tend to exhibit similar accents and rates of speech, and they are often associated with people’s social identity (Giles, Coupland, & Coupland, 1991). So, if you have lived in different places where people have somewhat different accents (e.g., the United States and the United Kingdom), you might have noticed that when you speak with Americans you use an American accent but when you speak with Britons you use a British accent.
Pickering and Garrod (2004) suggest that these interpersonal alignments at different levels of language use can activate similar situation models in the minds of those who are engaged in a conversation. Situation models are representations about the topic of a conversation. So, if you are talking about Gary and Mary with your friends, you might have in your mind a situation model of Gary giving Mary a ring. Pickering and Garrod’s theory suggests that as you describe a situation using language, others in the conversation begin to use similar words and grammar, and many other aspects of language use converge. As you all do so, similar situation models begin to be built in everyone’s mind through the mechanism known as priming. Priming occurs when your thinking about one concept (e.g., ring) reminds you about other related concepts (e.g., marriage or wedding ceremony). So, if everyone in the conversation knows about Gary, Mary, and the usual course of events associated with a ring — involving engagement, wedding, marriage, and so on — everyone is likely to construct a shared situation model about Gary and Mary. Thus, making use of our highly developed interpersonal ability to imitate (i.e., executing the same action as another person) and cognitive ability to infer (i.e., one idea leading to other ideas), we humans coordinate our common ground, share situation models, and communicate with each other.
What Do We Talk About?
What are humans doing when they are talking? Surely, we can communicate about ordinary things such as what to have for dinner, but also more complex and abstract things such as the meaning of life and death, liberty, equality, fraternity, and many other philosophical thoughts. When naturally occurring conversations were actually observed (Dunbar, Marriott, & Duncan, 1997), a staggering 60–70% of everyday conversation, for both men and women, turned out to be gossip — people talk about themselves and others whom they know (Figure IL.17). Just like Adam and Ben, more often than not, people use language to communicate about their social world.

Gossip may sound trivial and seem to belittle our noble ability for language, surely one of the most remarkable human abilities of all that distinguish us from other animals. On the contrary, some have argued that gossip — activities used to think and communicate about our social world — is one of the most critical uses to which language has been put. Robin Dunbar speculated that gossiping is the human equivalent of grooming, that is, when monkeys and primates attend to each other by cleaning each other’s fur. Dunbar (1996) argued that it is an act of socialising, signaling the importance of one’s partner. Furthermore, by gossiping, humans can communicate and share their representations about their social world: who their friends and enemies are, what the right thing to do is under what circumstances, and so on. By doing that, they can regulate their social world, making more friends and enlarging their own group — often called the ingroup, the group to which one belongs — against other groups — known as outgroups — that are more likely to be one’s enemies. Dunbar has argued that it is these social effects that have given humans an evolutionary advantage and larger brains, which, in turn, help humans to think more complex and abstract thoughts and, more importantly, maintain larger ingroups. Dunbar (1993) estimated an equation that predicts average group size of nonhuman primate genera from the size of their average neocortex, which is the part of the brain that supports higher order cognition. In line with his social brain hypothesis, Dunbar showed that those primate genera that have larger brains tend to live in larger groups. Furthermore, using the same equation, Dunbar was able to estimate the group size that human brains can support, which turned out to be about 150 — approximately the size of modern hunter-gatherer communities. Dunbar’s argument is that language, brain, and human group living have co-evolved; language and human sociality are inseparable.
Dunbar’s hypothesis is controversial. Nonetheless, our everyday language use often ends up maintaining the existing structure of intergroup relationships. Language use can have implications for the ways in which we construe our social world. For one thing, there are subtle cues that people use to convey the extent to which someone’s action is just a special case in a particular context or a pattern that occurs across many contexts, like a character trait. According to Gün Semin and Klaus Fiedler (1988), someone’s action can be described by an action verb that describes a concrete action (e.g., she runs), a state verb that describes the actor’s psychological state (e.g., she likes running), an adjective that describes the actor’s personality (e.g., she is athletic), or a noun that describes the actor’s role (e.g., she is an athlete). Depending on whether a verb, an adjective, or a noun is used, speakers can convey the permanency and stability of an actor’s tendency to act in a certain way — verbs convey particularity, whereas adjectives convey permanency. Intriguingly, people tend to describe positive actions of their ingroup members using adjectives (e.g., she is generous) rather than verbs (e.g., she gave a tall man some change), and negative actions of outgroup members using adjectives (e.g., she is cruel) rather than verbs (e.g., she kicked a dog). Anne Maass, Daniela Salvi, Luciano Arcuri, and Gün Semin (1989) called this a linguistic intergroup bias, which can produce and reproduce the representation of intergroup relationships by painting a picture favouring the ingroup. That is, ingroup members are typically good, and if they do anything bad, that’s more an exception in special circumstances; in contrast, outgroup members are typically bad, and if they do anything good, that’s more an exception.
People tend to tell stories that evoke strong emotions (Rimé, Mesquita, Boca, & Philoppot, 1991). Such emotive stories can then spread far and wide through people’s social networks. When a group of 33 psychology students visited a city morgue — no doubt an emotive experience for many — they each told their experience to about six people on average; each of the people who heard about it told one person, who in turn told another person on average. By the third retelling of the morgue visit, 881 people had heard about this in their community within 10 days. If everyone in society is connected with one another by six degrees of separation (Travers & Milgram, 1969) and if a chain letter can travel hundreds of steps via the Internet (Liben-Nowell & Kleinberg, 2008), the possibility of emotive gossip traveling through a vast social network is not a fantasy. Indeed, urban legends that evoke strong feelings of disgust tend to spread in cyberspace and become more prevalent on the Internet (Heath, Bell, & Sternberg, 2001).
In addition, when people exchange their gossip, it can spread through broader social networks. If gossip is transmitted from one person to another, the second person can transmit it to a third person, who then transmits it to a fourth, and so on through a chain of communication. This often happens for emotive stories. If gossip is repeatedly transmitted and spread, it can reach a large number of people. When stories travel through communication chains, they tend to become conventionalised (Bartlett, 1932). A Native American tale (the cultural origin of the tale is not specified) of the “War of the Ghosts” recounts a warrior’s encounter with ghosts traveling in canoes and his involvement with their ghostly battle. He is shot by an arrow but doesn’t die, returning home to tell the tale. After his narration, however, he becomes still, a black thing comes out of his mouth, and he eventually dies. When it was told to a student in England in the 1920s and retold from memory to another person, who, in turn, retold it to another and so on in a communication chain, the mythic tale became a story of a young warrior going to a battlefield, in which canoes became boats, and the black thing that came out of his mouth became simply his spirit (Bartlett, 1932). In other words, information transmitted multiple times was transformed to something that was easily understood by many; information was assimilated into the common ground shared by most people in the linguistic community. More recently, Yoshihisa Kashima (2000) conducted a similar experiment using a story that contained a sequence of events that described a young couple’s interaction that included both stereotypical and counter-stereotypical actions (e.g., a man watching sports on TV on Sunday as opposed to a man vacuuming the house). After the retelling of this story, much of the counter-stereotypical information was dropped, and stereotypical information was more likely to be retained. Because stereotypes are part of the common ground shared by the community, this finding too suggests that conversational retellings are likely to reproduce conventional content.
Psychological Consequences of Language Use
What are the psychological consequences of language use? When people use language to describe an experience, their thoughts and feelings are profoundly shaped by the linguistic representation that they have produced rather than the original experience (Holtgraves & Kashima, 2008). For example, Jamin Halberstadt (2003) showed a picture of a person displaying an ambiguous emotion and examined how people evaluated the displayed emotion. When people verbally explained why the target person was expressing a particular emotion, they tended to remember the person as feeling that emotion more intensely than when they simply labelled the emotion.

Thus, constructing a linguistic representation of another person’s emotion apparently biased the speaker’s memory of that person’s emotion. Furthermore, linguistically labelling one’s own emotional experience appears to alter the speaker’s neural processes. When people linguistically labelled negative images, the amygdala — a brain structure that is critically involved in the processing of negative emotions such as fear — was activated less than when they were not given a chance to label them (Lieberman et al., 2007). Potentially because of these effects of verbalising emotional experiences, linguistic reconstructions of negative life events can have some therapeutic effects on those who suffer from the traumatic experiences (Pennebaker & Seagal, 1999). Sonja Lyubomirsky, Lorie Sousa, and Rene Dickerhoof (2006) found that writing and talking about negative past life events improved people’s psychological well-being, but just thinking about them worsened it. Furthermore, if a certain type of language use (i.e., linguistic practice) is repeated by a large number of people in a community, it can potentially have a significant effect on their thoughts and actions (Holtgraves & Kashima, 2008). This notion is often called Sapir-Whorf hypothesis (Sapir, 1921; Whorf, 1956). For instance, if you are given a description of a man, Steven, as having greater than average experience of the world (e.g., well-traveled, varied job experience), a strong family orientation, and well-developed social skills, how do you describe Steven? Do you think you can remember Steven’s personality five days later? It will probably be difficult, but if you know Chinese and are reading about Steven in Chinese (the original paper does not specify whether this is Mandarin or Cantonese), as Curt Hoffman, Ivy Lau, and David Johnson (1986) showed, the chances are that you can remember him well. This is because English does not have a word to describe this kind of personality, whereas Chinese does: shì gù. This way, the language you use can influence your cognition. In its strong form, it has been argued that language determines thought, but this is probably wrong. Language does not completely determine our thoughts — our thoughts are far too flexible for that — but habitual uses of language can influence our habit of thought and action. For instance, some linguistic practice seems to be associated even with cultural values and social institutions, like dropping pronouns. Pronouns such as “I” and “you” are used to represent the speaker and listener of a speech in English. In an English sentence, these pronouns cannot be dropped if they are used as the subject of a sentence. So, for instance, “I went to the movie last night” is fine, but “Went to the movie last night” is not in standard English. However, in other languages such as Japanese, pronouns can be, and in fact often are, dropped from sentences. It turns out that people living in those countries where pronoun drop languages are spoken tend to have more collectivistic values (e.g., employees having greater loyalty toward their employers) than those who use non–pronoun drop languages such as English (Kashima & Kashima, 1998). It was argued that the explicit reference to “you” and “I” may remind speakers of the distinction between the self and other, and it may remind speakers of the differentiation between individuals. Such a linguistic practice may act as a constant reminder of the cultural value, which, in turn, may encourage people to perform the linguistic practice.
An example of evidence for Sapir-Whorf hypothesis comes from a comparison between English and Mandarin speakers (Boroditsky, 2000). In English, time is often metaphorically described in horizontal terms. For instance, good times are ahead of us, or hardship can be left behind us. We can move a meeting forward or backward. Mandarin speakers use similar horizontal metaphors too, but vertical metaphors are also used. So, for instance, the last month is called shàng gè yuè or “above month,” and the next month, xià gè yuè or “below month.” To put it differently, the arrow of time flies horizontally in English, but it can fly both horizontally and vertically in Chinese. Does this difference in language use affect English and Chinese speakers’ comprehension of language?
This is what Boroditsky (2000) found. First, English and Mandarin speakers’ understanding of sentences that use a horizontal positioning (e.g., June comes before August) did not differ much. When they were first presented with a picture that implies a horizontal positioning (e.g., the black worm is ahead of the white worm), they could read and understand them faster than when they were presented with a picture that implies a vertical positioning (e.g., the black ball is above the white ball). This implies that thinking about the horizontal positioning, when described as ahead or behind, equally primed (i.e., reminded) both English and Chinese speakers of the horizontal metaphor used in the sentence about time. However, English and Chinese speakers’ comprehension differed for statements that do not use a spatial metaphor (e.g., August is later than June). When primed with the vertical spatial positioning, Chinese speakers comprehended these statements faster, but English speakers more slowly, than when they were primed with the horizontal spatial positioning. Apparently, English speakers were not used to thinking about months in terms of the vertical line, when described as above or below. Indeed, when they were trained to do so, their comprehension was similar to Chinese speakers (Boroditsky, Fuhrman, & McCormick, 2010).
The idea that language and its structures influence and limit human thought is called linguistic relativity. The most frequently cited example of this possibility was proposed by Benjamin Whorf (1897–1941), a linguist who was particularly interested in Aboriginal languages. Whorf argued that the Inuit people of Canada had many words for snow, whereas English speakers have only one, and that this difference influenced how the different cultures perceived snow. Whorf argued that the Inuit perceived and categorised snow in finer details than English speakers possibly because the English language constrained perception. Although the idea of linguistic relativism seemed reasonable, research has suggested that language has less influence on thinking than might be expected. For one, in terms of perceptions of snow, although it is true that the Inuit do make more distinctions among types of snow than English speakers do, the latter also make some distinctions (e.g., think of words like powder, slush, whiteout, and so forth). It is also possible that thinking about snow may influence language, rather than the other way around.
In a more direct test of the possibility that language influences thinking, Eleanor Rosch (1973) compared people from the Dani culture of New Guinea, who have only two terms for colour, dark and bright, with English speakers who use many more terms. Rosch hypothesised that if language constrains perception and categorisation, then the Dani should have a harder time distinguishing colours than English speakers would. However, Rosch’s research found that when the Dani were asked to categorise colours using new categories, they did so in almost the same way that English speakers did. Similar results were found by Michael Frank, Daniel Everett, Evelina Fedorenko, and Edward Gibson (2008), who showed that the Amazonian tribe known as the Pirahã, who have no linguistic method for expressing exact quantities, not even the number one, were nevertheless able to perform matches with large numbers without problem.
Although these data led researchers to conclude that the language we use to describe colour and number does not influence our understanding of the underlying sensation, another more recent study has questioned this assumption. Debi Roberson, Ian Davies, and Jules Davidoff (2000) conducted another study with Dani participants and found that, at least for some colours, the names that they used to describe colours did influence their perceptions of the colours. Other researchers continue to test the possibility that our language influences our perceptions, and perhaps even our thoughts (Levinson, 1998), and yet the evidence for this possibility is, as of now, mixed.
Development of Language
Psychology in Everyday Life: The Case of Genie
In the fall of 1970, a social worker in the Los Angeles area found a 13-year-old girl who was being raised in extremely neglectful and abusive conditions. The girl, who came to be known as Genie, had lived most of her life tied to a potty chair or confined to a crib in a small room that was kept closed with the curtains drawn. For a little over a decade, Genie had virtually no social interaction and no access to the outside world. As a result of these conditions, Genie was unable to stand up, chew solid food, or speak (Fromkin, Krashen, Curtiss, Rigler, & Rigler, 1974; Rymer, 1993). The police took Genie into protective custody.
Genie’s abilities improved dramatically following her removal from her abusive environment, and early on, it appeared she was acquiring language — much later than would be predicted by critical period hypotheses that had been posited at the time (Fromkin et al., 1974). Genie managed to amass an impressive vocabulary in a relatively short amount of time. However, she never mastered the grammatical aspects of language (Curtiss, 1981). Perhaps being deprived of the opportunity to learn language during a critical period impeded Genie’s ability to fully acquire and use language. Genie’s case, while not conclusive, suggests that early language input is needed for language learning. This is also why it is important to determine quickly if a child is deaf and to begin immediately to communicate in sign language in order to maximise the chances of fluency (Mayberry, Lock, & Kazmi, 2002).
All children with typical brains who are exposed to language will develop it seemingly effortlessly. They do not need to be taught explicitly how to conjugate verbs, they do not need to memorise vocabulary lists, and they will easily pick up any accent or dialect that they are exposed to. Indeed, children seem to learn to use language much more easily than adults do. You may recall that each language has its own set of phonemes that are used to generate morphemes, words, and so on. Babies can discriminate among the sounds that make up a language (e.g., they can tell the difference between the “s” in vision and the “ss” in fission), and they can differentiate between the sounds of all human languages, even those that do not occur in the languages that are used in their environments. However, by the time that they are about one year old, they can only discriminate among those phonemes that are used in the language or languages in their environments (Jensen, 2011; Werker & Lalonde, 1988; Werker & Tees, 2002).
Learning Language
Language learning begins even before birth because the fetus can hear muffled versions of speaking from outside the womb. Christine Moon, Robin Cooper, and William Fifer (1993) found that infants only two days old sucked harder on a pacifier when they heard their mothers’ native language being spoken — even when strangers were speaking the languages — than when they heard a foreign language. Babies are also aware of the patterns of their native language, showing surprise when they hear speech that has different patterns of phonemes than those they are used to (Saffran, Aslin, & Newport, 2004).
During the first year or so after birth, long before they speak their first words, infants are already learning language. One aspect of this learning is practice in producing speech. By the time they are six to eight weeks old, babies start making vowel sounds (e.g., ooohh, aaahh, goo) as well as a variety of cries and squeals to help them practice.
At about seven months, infants begin babbling, which is to say they are engaging in intentional vocalisations that lack specific meaning. Children babble as practice in creating specific sounds, and by the time they are one year old, the babbling uses primarily the sounds of the language that they are learning (de Boysson-Bardies, Sagart, & Durand, 1984). These vocalisations have a conversational tone that sounds meaningful even though it is not. Babbling also helps children understand the social, communicative function of language (Figure IL.19). Children who are exposed to sign language babble in sign by making hand movements that represent real language (Petitto & Marentette, 1991).

At the same time that infants are practicing their speaking skills by babbling, they are also learning to better understand sounds and eventually the words of language. One of the first words that children understand is their own name, usually by about six months, followed by commonly used words like “bottle,” “mama,” and “doggie” by 10 to 12 months (Mandel, Jusczyk, & Pisoni, 1995).
The infant usually produces their first words at about one year of age. It is at this point that the child first understands that words are more than sounds — they refer to particular objects and ideas. By the time children are two years old, they have a vocabulary of several hundred words, and by kindergarten their vocabularies have increased to several thousand words. By Grade 5, most children know about 50,000 words; by the time they are in university, most know about 200,000. This may vary for people who don’t attend university or complete higher education.
The early utterances of children contain many errors, for instance, confusing /b/ and /d/, or /c/ and /z/, and the words that children create are often simplified, in part because they are not yet able to make the more complex sounds of the real language (Dobrich & Scarborough, 1992). Children may say “keekee” for kitty, “nana” for banana, and “vesketti” for spaghetti in part because it is easier. Often these early words are accompanied by gestures that may also be easier to produce than the words themselves. Children’s pronunciations become increasingly accurate between one and three years, but some problems may persist until school age.
Most of a child’s first words are nouns, and early sentences may include only the noun. “Ma” may mean “more milk please,” and “da” may mean “look, there’s Fido.” Eventually the length of the utterances increases to two words (e.g., “mo ma” or “da bark”), and these primitive sentences begin to follow the appropriate syntax of the native language.
Because language involves the active categorisation of sounds and words into higher level units, children make some mistakes in interpreting what words mean and how to use them. In particular, they often make overextensions of concepts, which means they use a given word in a broader context than appropriate. For example, a child might at first call all adult men “daddy” or all animals “doggie.”
Children also use contextual information, particularly the cues that parents provide, to help them learn language. Infants are frequently more attuned to the tone of voice of the person speaking than to the content of the words themselves and are aware of the target of speech. Janet Werker, Judith Pegg, and Peter McLeod (1994) found that infants listened longer to a woman who was speaking to a baby than to a woman who was speaking to another adult.
Children learn that people are usually referring to things that they are looking at when they are speaking (Baldwin, 1993) and that the speaker’s emotional expressions are related to the content of their speech. Children also use their knowledge of syntax to help them figure out what words mean. If a child sees an adult point to a strange object and hears them say, “this is a dirb,” they will infer that a “dirb” is a thing, but if they hear them say, “this is a one of those dirb things,” they will infer that it refers to the colour or another characteristic of the object. Additionally, if they hear the word “dirbing,” they will infer that “dirbing” is something that we do (Waxman, 1990).
How Children Learn Language: Theories of Language Acquisition
Psychological theories of language learning differ in terms of the importance they place on nature versus nurture, yet it is clear that both matter. Children are not born knowing language; they learn to speak by hearing what happens around them. Human brains, unlike those of any other animal, are wired in a way that leads them, almost effortlessly, to learn language.
Perhaps the most straightforward explanation of language development is that it occurs through principles of learning, including association, reinforcement, and the observation of others (Skinner, 1965). There must be at least some truth to the idea that language is learned because children learn the language that they hear spoken around them rather than some other language. Also supporting this idea is the gradual improvement of language skills with time. It seems that children modify their language through imitation, reinforcement and shaping, as would be predicted by learning theories.
However, language cannot be entirely learned. For one, children learn words too fast for them to be learned through reinforcement. Between the ages of 18 months and five years, children learn up to 10 new words every day (Anglin, 1993). More importantly, language is more generative than it is imitative. Generativity refers to the fact that speakers of a language can compose sentences to represent new ideas that they have never before been exposed to. Language is not a predefined set of ideas and sentences that we choose when we need them, but rather a system of rules and procedures that allows us to create an infinite number of statements, thoughts, and ideas, including those that have never previously occurred. When a child says that they “swimmed” in the pool, for instance, they are showing generativity. No native speaker of English would ever say “swimmed,” yet it is easily generated from the normal system of producing language.
Other evidence that refutes the idea that all language is learned through experience comes from the observation that children may learn languages better than they ever hear them. Deaf children whose parents do not use sign language very well nevertheless are able to learn it perfectly on their own, and they may even make up their own language if they need to (Goldin-Meadow & Mylander, 1998). A group of deaf children in a school in Nicaragua, whose teachers could not sign, invented a way to communicate through made-up signs (Senghas, Senghas, & Pyers, 2005). The development of this new Nicaraguan Sign Language has continued and changed as new generations of students have come to the school and started using the language. Although the original system was not a real language (i.e., it was created from scratch and did not descend from our ancestral past), it is becoming closer and closer every year, showing the development of a new language in modern times.
The linguist Noam Chomsky is a believer in the nature approach to language, arguing that human brains contain a language acquisition device that includes a universal grammar that underlies all human language (Chomsky, 1965, 1972). According to this approach, each of the many languages spoken around the world — there are between 6,000 and 8,000 — is an individual example of the same underlying set of procedures that are hardwired into human brains. Chomsky’s account proposes that children are born with a knowledge of general rules of syntax that determine how sentences are constructed and then coordinate with the language the child is exposed to.
Chomsky differentiates between the deep structure of an idea — how the idea is represented in the fundamental universal grammar that is common to all languages — and the surface structure of the idea — how it is expressed in any one language. Once we hear or express a thought in surface structure, we generally forget exactly how it happened. At the end of a lecture, you will remember a lot of the deep structure (i.e., the ideas expressed by the instructor), but you cannot reproduce the surface structure (i.e., the exact words that the instructor used to communicate the ideas).
Although there is general agreement among psychologists that babies are genetically programmed to learn language, there is still debate about Chomsky’s idea that there is a universal grammar that can account for all language learning. Nicholas Evans and Stephen Levinson (2009) surveyed the world’s languages and found that none of the presumed underlying features of the language acquisition device were entirely universal. In their search, they found languages that did not have noun or verb phrases, that did not have tenses (e.g., past, present, future), and even some that did not have nouns or verbs at all, even though a basic assumption of a universal grammar is that all languages should share these features.
Bilingualism and Cognitive Development
Bilingualism, which is the ability to speak two languages, is becoming more and more frequent in the modern world. Nearly one-half of the world’s population, including 17% of Canadian citizens, grows up bilingual.
In Canada, education is under provincial jurisdiction; however, the federal government has been a strong supporter of establishing Canada as a bilingual country and has helped pioneer the French immersion programs in the public education systems throughout the country. In contrast, many US states have passed laws outlawing bilingual education in schools based on the idea that students will have a stronger identity with the school, the culture, and the government if they speak only English. This is, in part, based on the idea that speaking two languages may interfere with cognitive development. There appears to be little evidence for such an assertion. In fact, throughout most of human history, human beings have lived in multilingual societies. In literate societies, it was common for people to use one language for everyday use and another for official or literary purposes (Sanskrit in Ancient India and Southeast Asia, Greek in the Roman empire, Latin in Western Europe, Persian in the Ottoman and Mughal empires, and Classical Arabic in the Islamic World were all used as academic language while other languages were used in day-to-day interactions).
A variety of minority language immersion programs are now offered across the country depending on need and interest. In British Columbia, for instance, the city of Vancouver established a new bilingual Mandarin Chinese-English immersion program in 2002 at the elementary school level in order to accommodate Vancouver’s both historic and present strong ties to the Mandarin-speaking world. Similar programs have been developed for both Hindi and Punjabi to serve the large South Asian cultural community in the city of Surrey. By default, most schools in British Columbia teach in English, with French immersion options available. In both English and French schools, one can study and take government exams in Japanese, Punjabi, Mandarin, French, Spanish, and German at the secondary level.
Some early psychological research showed that, when compared with monolingual children, bilingual children performed more slowly when processing language, and their verbal scores were lower. However, these tests were frequently given in English, even when this was not the child’s first language, and the children tested were often of lower socioeconomic status than the monolingual children (Andrews, 1982).
More current research that has controlled for these factors has found that, although bilingual children may, in some cases, learn language somewhat more slowly than do monolingual children (Oller & Pearson, 2002), bilingual and monolingual children do not significantly differ in the final depth of language learning, nor do they generally confuse the two languages (Nicoladis & Genesee, 1997). In fact, participants who speak two languages have been found to have better cognitive functioning, cognitive flexibility, and analytic skills in comparison to monolinguals (Bialystok, 2009). Research has also found that learning a second language produces changes in the area of the brain in the left hemisphere that is involved in language (Figure IL.20), such that this area is denser and contains more neurons (Mechelli et al., 2004). Furthermore, the increased density is stronger in those individuals who are most proficient in their second language and who learned the second language earlier. Thus, rather than slowing language development, learning a second language seems to increase cognitive abilities.



Biology of Language
For the 90% of people who are right-handed, language is stored and controlled by the left cerebral cortex, while for some left-handers this pattern is reversed. These differences can easily be seen in the results of neuroimaging studies that show that listening to and producing language creates greater activity in the left hemisphere than in the right. Broca’s area, an area in front of the left hemisphere near the motor cortex, is responsible for language production (Figure IL.21). This area was first localized in the 1860s by the French physician Paul Broca, who studied patients with lesions to various parts of the brain. Wernicke’s area, an area of the brain next to the auditory cortex, is responsible for language comprehension.

Evidence for the importance of Broca’s area and Wernicke’s area in language is seen in patients who experience aphasia, a condition in which language functions are severely impaired. People with Broca’s aphasia have difficulty producing speech, whereas people with damage to Wernicke’s area can produce speech, but what they say makes no sense, and they have trouble understanding language.
Can Animals Learn Language?
Nonhuman animals have a wide variety of systems of communication. Some species communicate using scents; others use visual displays, such as baring the teeth, puffing up the fur, or flapping the wings; and still others use vocal sounds. Male songbirds, such as canaries and finches, sing songs to attract mates and to protect territory, and chimpanzees use a combination of facial expressions, sounds, and actions, such as slapping the ground, to convey aggression (de Waal, 1989). Honeybees use a waggle dance to direct other bees to the location of food sources (von Frisch, 1956). The language of vervet monkeys is relatively advanced in the sense that they use specific sounds to communicate specific meanings. Vervets make different calls to signify that they have seen either a leopard, a snake, or a hawk (Seyfarth & Cheney, 1997). Despite their wide abilities to communicate, efforts to teach animals to use language have had only limited success. One of the early efforts was made by Catherine and Keith Hayes (1952), who raised a chimpanzee named Viki in their home along with their own children, but Viki learned little and could never speak. Researchers speculated that Viki’s difficulties might have been, in part, because she could not create the words in her vocal cords. Subsequent attempts were made to teach primates to speak using sign language or boards on which they could point to symbols.
In another famous case, an African grey parrot called Alex was able to identify and name certain objects, and even categorise them in terms of shape or colour (Pepperberg, 2010). Alex used the words he had been taught and eventually began to use other words that he had not been trained for; this was evidence that he was picking up words and using them correctly merely by being exposed to them. Alex was also able to make rudimentary phrases without being taught them specifically.
Allen and Beatrix Gardner worked for many years to teach a chimpanzee named Washoe to sign using ASL. Washoe, who lived to be 42 years old, could label up to 250 different objects and make simple requests and comments, such as “please tickle” and “me sorry” (Fouts, 1997). Washoe’s adopted daughter Loulis, who was never exposed to human signers, learned more than 70 signs simply by watching her mother sign.
The most proficient nonhuman language user is Kanzi, a bonobo who lives at the Language Learning Center at Georgia State University (Savage-Rumbaugh & Lewin, 1994; Raffaele, 2006). The following YouTube link shows that Kanzi has a propensity for language that is in many ways similar to humans.
Watch this video: Kanzi and Novel Sentences (2 minutes)
“Kanzi and Novel Sentences” video by IowaPrimate .LearningSanctuary is licensed under the Standard YouTube licence.
Kanzi learned faster when he was younger than when he got older. He learns by observation, and he can use symbols to comment on social interactions rather than simply for food treats. Kanzi can also create elementary syntax and understand relatively complex commands. Kanzi can make tools and can even play the video game Pac-Man.
Yet even Kanzi does not have a true language in the same way that humans do. Human babies learn words faster and faster as they get older, but Kanzi does not. Each new word he learns is almost as difficult as the one before. Kanzi usually requires many trials to learn a new sign, whereas human babies can speak words after only one exposure. Kanzi’s language is focused primarily on food and pleasure and only rarely on social relationships. Although he can combine words, he generates few new phrases and cannot master syntactic rules beyond the level of about a two-year-old human child (Greenfield & Savage-Rumbaugh, 1991).
In summary, although many animals communicate, none of them has a true language. With some exceptions, the information that can be communicated in nonhuman species is limited primarily to displays of liking or disliking and related to basic motivations of aggression and mating. Humans also use this more primitive type of communication — in the form of nonverbal behaviours such as eye contact, touch, hand signs, and interpersonal distance — to communicate their like or dislike for others, but they, unlike animals, also supplant this more primitive communication with language. Although other animal brains share similarities to ours, only the human brain is complex enough to create language. What is perhaps most remarkable is that although language never appears in nonhumans, language is universal in humans. All humans, unless they have a profound brain abnormality or are completely isolated from other humans, learn language.
Source: Adapted from Kashima (2020).
Image Descriptions
Figure IL.12. English Consonants image description: The consonants are between two brackets ().
| Bilabial | Labio-dental | Dental | Alveolar | Post-alveolar | Palatal | Velar | Glottal | |
|---|---|---|---|---|---|---|---|---|
| Nasal | (m)um | (n)ip | s(ing) | |||||
| Stop | (p)ot, (b)in | (t)ip, (d)ip | (k)it, (g)et | |||||
| Affricate | (ch)ip, (j)et | |||||||
| Fricative | (f)an, (v)an | (th)in, (th)is | (s)ip, (z)ip | ship, vision | lo(ch) (only found in some dialects in Scotland) | (h)ip | ||
| Approximant | (r)ose | (r)ose | (y)awn | (w)et | ||||
| Lateral | (l)ip |
Figure IL.14. Different type of morphology image description:
Provides examples of the morphological typology of Mandarin, an isolating language, Tamil, an agglutinative language, Spanish, a fusional language, and Mohawk, a polysynthetic language. The image illustrates the meanings of the morpheme components of the words or phrases, and how they combine to express meaning.
- Isolating language (Mandarin): měi (America), guó (country), and rén (person) combined into měi guó rén which means “American”.
- Agglutinative language (Tamil): peːsu (speak), kir (present), and eːn (1st person singular) combined into peːsu kir eːn which means “I am speaking”.
- Fusional (Spanish): ind (present indicative), hablar (speak) and yo (1st person singular) combined into hablo which means “I speak”.
- Polysynthetic (Mohawk): s (again), a (past), hųwa(she/him), nho (door), tų (close), kw (un), ahs (for), eʔ (perfective) combined into sahųwanhotųkwahseʔ which means “she opened the door for him again”.
Figure IL.15. Sentence Structure in English image description:
- S
- NP
- DET
- The
- N
- dog
- DET
- VP
- V
- likes
- NP
- John
- V
- NP
Image Attributions
Figure IL.10. Human Vocal Tract is an edited version of Mouth Anatomy by Patrick J. Lynch, medical illustrator, is licensed under a CC BY 2.5 licence.
Figure IL.11. Original image by Dinesh Ramood is licensed under a CC BY-NC-SA 4.0 license.
Figure IL.12. Original image by Dinesh Ramood is licensed under a CC BY-NC-SA 4.0 license.
Figure IL.13. Adapted from Wood, 1976, by Dinesh Ramood and is licensed under a CC BY-NC-SA 4.0 license.
Figure IL.14. Original image by Dinesh Ramood is licensed under a CC BY-NC-SA 4.0 license.
Figure IL.15. Original image by Dinesh Ramood is licensed under a CC BY-NC-SA 4.0 license.
Figure IL.16. CFF_3232 by Converse College is used under a CC BY-NC-ND 2.0 license.
Figure IL.17. Business Secrets News by Aqua Mechanical is used under a CC BY 2.0 license.
Figure IL.18. Over Coffee by Drew Herron is used under a CC BY-NC-SA 2.0 license.
Figure IL.19. Lucas, Age 2½, On the Phone to Mama by Lars Plougmann is used under a CC BY-SA 2.0 license.
Figure IL.20. Original image by Dinesh Ramood is licensed under a CC BY-NC-SA 4.0 license.
Figure IL.21. Original image by Dinesh Ramood is licensed under a CC BY-NC-SA 4.0 license.
To calculate this time, we used a reading speed of 150 words per minute and then added extra time to account for images and videos. This is just to give you a rough idea of the length of the chapter section. How long it will take you to engage with this chapter will vary greatly depending on all sorts of things (the complexity of the content, your ability to focus, etc).

{kind=link}